📋 JAVA 基础知识大盘点
注意,本文并非是面向初学者的学习教程,而是面向拥有一定基础(入门),或初级、中级 JAVA 开发人员,而整理出的一些 JAVA 基础相关的[关键性知识]{.label .primary},因此,部分知识点只会提出要点梗概,而不会关注具体代码示例和实现。本文的主要目的在于帮助已掌握相关知识的开发者们快速地进行知识回顾。
面向对象
Java 技术体系包括:
-
Java 程序设计语言
-
各种硬件平台上的 Java 虚拟机实现
-
Class 文件格式
-
Java 类库 API
-
来自商业机构和开源社区的第三方 Java 类库
什么是面向对象?
面向过程
面向过程 (Procedure Oriented) 是一种以过程为中心的编程思想。这些都是以什么正在发生为主要目标进行编程,不同于面向对象的是谁在受影响。与面向对象相对应的,即存在于早期版本 C 语言中的面向过程。面向过程开发的过程,有点类似于树状调用函数,树状的根节点主程序对函数进行层层调用。
面向过程的问题
-
复用性不佳
按过程来的话,不同过程中相似的代码也不好进行复用,前半段的过程中用到的逻辑,在后半段再次使用的话需要再写一遍,如果是相同的逻辑,修改也会出现很多复杂问题。
-
扩展性不易
相同的逻辑,如果要有两份相似逻辑,那在面向过程中,就很多时候需要写两份。
-
耦合度高
面向过程很难将内容剥离开。
面向对象
面向对象 (Object Oriented,OO) 是一种对现实世界理解和抽象的方法,是计算机编程技术发展到一定阶段后的产物。面向对象的编程方式使得每一个类都只做一件事。
面向对象的三大基本特征
-
封装
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
-
继承
继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来类的情况下对这些功能进行扩展。通过继承创建的新类称为「子类」或「派生类」,被继承的类称为「基类」、「父类」或「超类」。要实现继承,可以通过 继承和组合 来实现。
-
多态
多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单说就是一句话:允许将子类类型的指针赋值给父类类型的指针。
实现多态,有两种方式,覆盖和重载。两者的区别在于:覆盖在运行时决定,重载是在编译时决定。并且覆盖和重载的机制不同。在 Java 中,重载方法的签名必须不同于原先方法的,但对于覆盖签名必须相同。
Java 如何实现平台无关
平台无关性就是一种语言在计算机上的运行不受平台的约束,一次编译,到处执行(Write Once ,Run Anywhere)。对于 Java 的平台无关性的支持,就像对安全性和网络移动性的支持一样,是分布在整个 Java 体系结构中的。其中扮演者重要的角色的有 Java 语言规范、Class 文件、Java 虚拟机(JVM)等。
JVM 还支持哪些语言
-
Kotlin
-
Clojure
-
Groovy
-
JRuby
-
Jython
-
Scala
值传递
-
形式参数:
是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数。
-
实际参数:
在调用有参函数时,主调函数和被调函数之间有数据传递关系。在主调函数中调用一个函数时,函数名后面括号中的参数称为“实际参数”。
值传递
在方法被调用时,实参通过形参把它的内容副本传入方法内部,此时形参接收到的内容是实参值的一个拷贝,因此在方法内对形参的任何操作,都仅仅是对这个副本的操作,不影响原始值的内容。
引用传值
「引用」也就是指向真实内容的地址值,在方法调用时,实参的地址通过方法调用被传递给相应的形参,在方法体内,形参和实参指向同一块内存地址,对形参的操作会影响的真实内容。
为什么说 Java 中只有值传递
Java 中的引用传递其实还是值传递的,只不过对于对象参数,值的内容是对象的引用。简单点说,Java 中的传递,是值传递,而这个值,实际上是对象的引用。所以我们可以说 Java 的传递是按共享传递,或者说 Java 中的传递是值传递。
三大基本特征
封装、继承、多态是 Java 面向对象的三大基本特征。
方法重写与重载
| 区别 | 重载 | 重写 |
|---|---|---|
| 英文 | Overload | Override |
| 目的 | 增加程序的可读性 | 提供其超级类已经提供的方法的特定实现 |
| 范围 | 发生在一个类中 | 发生在继承类中 |
| 参数 | 参数必须不同 | 参数必须相同 |
Java 的继承与实现
-
继承
继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力。Java 继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。继承只能单继承。
-
实现
如果多个类处理的目标是一样的,但是处理的方法方式不同,那么就定义一个接口,也就是一个标准,让他们的实现这个接口,各自实现自己具体的处理方法来处理那个目标。实现可以多实现。
构造函数
构造函数可以叫做构造器,它的函数名与类名相同,不用定义返回值类型,也没有具体的返回值。构造函数是在构建创造对象时调用函数,作用是可以给对象进行初始化,创建对象都必须要通过构造函数初始化。
-
默认构造函数
一个类中如果没有定义过构造函数,那么该类会有一个默认的空参数构造函数。如果在类中定义了指定的构造函数,那么该类中的默认构造函数就没有了。
变量
- 类变量
静态变量即类变量,位于方法区,为所有对象共享,共享一份内存,一旦静态变量被修改,其他对象均对修改可见,故线程非安全。类变量又称全局变量或静态变量,需要使用 static 关键字修饰。类级变量在类定义后就已经存在,占用内存空间,可以通过类名来访问,不需要实例化。
-
成员变量
-
成员变量定义在类中,在整个类中都可以被访问。
-
成员变量随着对象的建立而建立,随着对象的消失而消失,存在于对象所在的堆内存中。
-
成员变量有默认初始化值。
-
实例化后才会分配内存空间,才能访问。
成员变量 = 基本数据类型变量 + 实例变量。
实例变量:单例模式(只有一个对象实例存在)线程非安全,非单例线程安全。
- 局部变量
因为局部变量存在于方法内部,不会与其他线程共享,即不会存在并发问题,因此是线程安全带。这种解决问题的技术也叫做线程封闭。
-
局部变量只定义在局部范围内,如:函数内,语句内等,只在所属的区域有效。
-
局部变量存在于栈内存中,作用的范围结束,变量空间会自动释放。
-
局部变量没有默认初始化值。
在使用变量时需要遵循 就近原则,首先在局部范围查找,接着在成员位置找。
作用域
在 Java 中,变量的作用域分为四个级别:类级、对象实例级、方法级、块级。
成员变量或方法的作用域
-
public 表明该成员变量或者方法对所有类或者对象都是可见的,所有类或者对象都可以直接访问。
-
private 表明该成员变量或者方法是私有的,只有当前类对其具有访问权限,除此之外的类或者对象都没有访问权限。
-
protected 表明该成员变量或者方法只对自己及其子类可见,即自己和子类具有访问权限。除此之外的都没有访问权限。
-
default 表明该成员变量或者方法对自己或者与其位于同一包内的类可见。若父类和子类位于同一包内,则子类对于父类的 default 成员变量或者方法具有访问权限,若位于不同包内,则没有访问权限。
五大基本原则
面向对象遵循五大基本原则:
-
单一职责原则
SRP(Single Responsibility Principle),是指一个类的功能单一,可以看做是低耦合高内聚思想的延伸。
-
开放封闭原则
OCP(Open-Close Principle),在设计一个类或者一个模块,在扩展性方便应当是开放的,而在更改性方面,则应当是封闭的。
-
里氏替换原则
LSP(Liskov Substitution Principle),任何基类可以出现的地方,子类一定可以出现。
-
依赖倒置原则
DIP(Dependency Inversion Principle),高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。
-
接口隔离原则
ISP(Interface Segregation Principle),接口端不应该依赖它不需要的接口,一个类对另一个类的依赖应该建立在最小的接口上。
Java 基础
基本数据类型
变量就是申请内存来存储值。也就是说,当创建变量的时候,需要在内存中申请空间。内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据。因此,通过定义不同类型的变量,可以在内存中储存整数、小数或者字符。Java 语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。
8 种基本数据类型
-
整数型
-
byte
-
int
-
short
-
long
-
-
浮点型
通常的浮点型数据在不声明的情况下都是 double 型的,如果要表示一个数据时 float 型的,可以在数据后面加上
F。浮点型的数据是不能完全精确的,有时候在计算时可能出现小数点最后几位出现浮动,这时正常的。-
float
float:单精度,在计算机中存储占用 4 字节,也 32 位,有效位数为 7 位。
-
double
double:双精度,在计算机中存储占用 8 字节,64 位,有效位数为 16 位。
-
-
字符型
-
char:char 有以下的初始化方式:
-
char ch = 'a';// 可以是汉字,因为是 Unicode 编码 -
char ch = 1010;// 可以是十进制数、八进制数、十六进制数等等。 -
char ch = '\0';// 可以用字符编码来初始化,如:’\0’ 表示结束符,它的 ASCII 码是 0,这句话的意思和 ch = 0 是一个意思。
-
-
-
布尔型
-
boolean
例:boolean flag = false;
-
-
基本数据类型对比
数据类型名称 占用字节 位数 默认值 取值范围 封装器类 byte 1 8 0 -2^7 - 2^7-1[-128 ~ 127] Byte short 2 16 0 -2^15 - 2^15-1 Short int 4 32 0 -2^31 - 2^31-1 Integer long 8 64 0L -2^63 - 2^63-1 Long float 4 32 0.0f -2^31 - 2^31-1 Float double 8 64 0.0d -2^63 - 2^63-1 Double char 2 16 ‘\u0000’ 0 - 2^16-1 Character boolean 1 8 false true、false Boolean
3 种引用数据类型
基本数据类型和引用数据类型的区别主要在存储方式上,基本数据类型在被创建时,在栈上给其划分一块内存,将数值直接存储在栈上;引用数据类型在被创建时,首先要在栈上给其引用(句柄)分配一块内存,而对象的具体信息都存储在堆内存上,然后由栈上面的引用指向堆中对象的地址。
-
类(对象)
-
接口
-
数组
自动拆装箱
自动类型转换时,转换前的数据类型的位数低于转换后的数据类型。
低 -------------------------------------------------------------> 高
byte,short,char—> int —> long—> float —> double
数据类型转换必须满足如下规则:
-
不能对 boolean 类型进行类型转换。
-
不能把对象类型转换成不相关类的对象。
-
由大到小会丢失精度:在把容量大的类型转换为容量小的类型时必须使用强制类型转换。
强制类型转换
-
条件是转换的数据类型必须是兼容的。
-
格式:(type)value type 是要强制类型转换后的数据类型
-
-
转换过程中可能导致溢出或损失精度,例如:
int i =128; byte b = (byte)i;// -128 -
浮点数到整数的转换是通过舍弃小数得到,而不是四舍五入。
包装类型
包装类型使得基本数据类型中的变量具有了类中对象的特征。基本数据类型,使用起来非常方便,但是没有对应的方法来操作这些基本类型的数据,可以使用一个类,把基本数据类型的数据装起来,这个类叫做包装类(wrapper)。这样我们可以调用类中的方法。
自动拆装箱
自动装箱时编译器调用 valueOf 方法将原始类型值转换成对象,同时自动拆箱时,编译器通过调用类似 intValue() ,doubleValue() 这类的方法将对象转换成原始类型值。
-
装箱(基本类型 -> 包装类)
通过包装类的构造器实现装箱(JDK1.5 之前)
Integer t = new Integer(10);通过字符串参数构造包装类对象实现装箱
Float f = new Float("4.56"); Long l = new Long("wer");// NumberFormatException自动装箱(JDK1.5 之后)
Integer i = 100;// 自动装箱 // 相当于编译器自动作以下的语法编译:Integer i = Integer.valueOf(100); -
拆箱(包装类 -> 基本类型)
调用包装类中的
.xxxValue()方法Integer t = 128; // 此时t就是一个包装类 System.out.println(t.intValue());//128自动拆箱
Integer i = 10; // 自动装箱 int t = i; // 自动拆箱,实际上执行了 int t = i.intValue();
Integer 的缓存机制
Integer 与 Integer 比较的时候,由于直接赋值的时候会进行自动装箱。那么这里就需要注意两个问题
-
Integer 进行自动装箱时,为其赋值处于区间 [-128, 127] 的整数时,数值将会直接被缓存在
IntegerCache中,而当进行赋值操作时,不会创建新的 Integer 对象,而是从缓存中获取已经创建好的 Integer 对象。 -
而当数值处于区间 [-128, 127] 的整数之外时,程序内部则会直接使用
new Integer()的方式来创建 Integer 对象。
String
字符串的不可变性
字符串的底层是使用数组存储的,数组的长度是不可变的,且使用 final 和 private 进行修饰,不能直接修改,String 也没有提供直接修改的方法。因此 String 一旦被创建,则不能被修改,所谓的修改也只是创建了新的对象。字符串常量对象存储在常量池中,常量池中的字符串是不会重复的。
JDK6 和 JDK7 中 substring 的原理及区别
-
JDK6 中的 substring
在 JDK6 中,String 类包含三个成员变量:
char value[],int offset,int count。他们分别用来存储真正的字符数组,数组的第一个位置索引以及字符串中包含的字符个数。当调用 substring 方法的时候,会创建一个新的 string 对象,但是这个 string 的值仍然指向堆中的同一个字符数组。这两个对象中只有 count 和 offset 的值是不同的。// JDK 6 String(int offset, int count, char value[]) { this.value = value; this.offset = offset; this.count = count; } public String substring(int beginIndex, int endIndex) { //check boundary return new String(offset + beginIndex, endIndex - beginIndex, value); }JDK 6 中的 substring 导致的问题
如果你有一个很长很长的字符串,但是当你使用 substring 进行切割的时候你只需要很短的一段。这可能导致性能问题,因为你需要的只是一小段字符序列,但是你却引用了整个字符串(因为这个非常长的字符数组一直在被引用,所以无法被回收,就可能导致内存泄露)。在 JDK 6 中,一般用以下方式来解决该问题,原理其实就是生成一个新的字符串并引用他。
x = x.substring(x, y) + ""; -
JDK7 中的 substring
在 JDK7 中,substring 方法会在堆内存中创建一个新的数组,substring 使用
new String创建了一个新字符串,避免对老字符串的引用。从而解决了内存泄露问题。// JDK 7 public String(char value[], int offset, int count) { //check boundary this.value = Arrays.copyOfRange(value, offset, offset + count); } public String substring(int beginIndex, int endIndex) { //check boundary int subLen = endIndex - beginIndex; return new String(value, beginIndex, subLen); }
replaceFirst、replaceAll、replace 区别
public class Replace {
public static void main(String[] args) {
String s = "my.test.txt";
System.out.println(s.replace(".", "#")); // replace将字符串中的. 都替换为 #
System.out.println(s.replaceAll(".", "#")); // replaceAll 用到了正则表达式,其中. 是任意字符的意思,所以结果是字符串全部替换为#
System.out.println(s.replaceFirst(".", "#")); // replaceFirst 用到了正则表达式, 其中. 是任意字符的意思,所以第一个字符被#号代替
System.out.println(s.replaceFirst("\\.", "#")); // 正则表达式中双杠是原生字符串的意思,所以结果是字符串中第一个. 被#代替得到
}
}String 对[+]的重载
Java 中实际没有运算符的重载,但是对 String 对象而言,它是可以直接+将两个 String 对象的字符串值相加。乍看起来这是对 + 的重载,但我们可以通过 class 文件看出,这只是 JVM 做的语法糖。
通过反编译的方式,不难发现,其实 String 对 + 的支持其实就是使用了 StringBuilder 以及他的 append 和 toString 两个方法。
字符串拼接的几种方式和区别
-
符号:+
Java 中的
+实际上是先构建一个StringBuilder对象,然后使用append()方法拼接字符串,最后调用toString()方法生成字符串,简单来说,其实现原理是使用StringBuilder.append。 -
concat
public String concat(String str) { int otherLen = str.length(); if (otherLen == 0) { return this; } int len = value.length; char buf[] = Arrays.copyOf(value, len + otherLen); str.getChars(buf, len); return new String(buf, true); }concat实现字符串拼接,首先是创建了一个字符数组,长度是已有字符串和待拼接字符串的长度之和,再把两个字符串的值复制到新的字符数组中,并使用这个字符数组创建一个新的 String 对象并返回。 -
StringBuilder.append
和 String 类类似,StringBuilder 类也封装了一个字符数组,与 String 不同的是,它并不是 final 的,所以他是可以修改的。另外,与 String 不同,字符数组中不一定所有位置都已经被使用,它有一个实例变量,表示数组中已经使用的字符个数。StringBuilder 的 append 方法会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展。
-
StringBuffer.append
StringBuffer 和 StringBuilder 类似,最大的区别就是 StringBuffer 是线程安全的,其 append 方法使用 synchronized 进行声明,说明是一个线程安全的方法。而 StringBuilder 则不是线程安全的。
-
StringUtils.join
其实也是通过
StringBuilder来实现的。
总结
-
如果不是在循环体中进行字符串拼接的话,直接使用
+就好了。 -
如果在并发场景中进行字符串拼接的话,要使用
StringBuffer来代替StringBuilder。
String.valueOf 和 Integer.toString 的区别
String.valueOf 和 Integer.toString 没有区别,因为前者内部是通过后者实现的。
public static String valueOf(int i) {
return Integer.toString(i);
}switch 对 String 的支持
其实 swich 只支持一种数据类型,那就是整型,其他数据类型都是转换成整型之后再使用 switch 的。
-
switch 对 int 的判断是直接比较整数的值。
-
switch 对 char 类型进行比较的时候,实际上比较的是 ascii 码,编译器会把 char 型变量转换成对应的 int 型变量。
-
switch 对字符串的 switch 是通过
equals()和hashCode()方法来实现的。
字符串池(String Pool)
字符串池的优点就是避免了相同内容的字符串的创建,节省了内存,省去了创建相同字符串的时间,同时提升了性能;另一方面,字符串池的缺点就是牺牲了 JVM 在常量池中遍历对象所需要的时间,不过其时间成本相比而言比较低。
常量池
常量池在 java 用于保存在编译期已确定的,已编译的 class 文件中的一份数据。它包括了关于类,方法,接口等中的常量,也包括字符串,执行器产生的常量也会放入常量池,故认为常量池是 JVM 的一块特殊的内存空间。
intern
intern() 方法返回字符串对象的规范化表示形式。它遵循以下规则:对于任意两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。
当字符串调用 intern() 方法时,这个方法会首先检查字符串池中是否存在该字符串,如果存在,则返回该字符串的引用;如果不存在,则将这个字符串添加到字符串池中,并返回这个字符串的引用。
String str1 = "a";
String str2 = "b";
String str3 = "ab";
String str4 = str1 + str2;
String str5 = new String("ab");
System.out.println(str5.equals(str3));// true 比较字符串的值
System.out.println(str5 == str3);// false 比较内存地址,str5使用new String方式创建了新的字符串对象
System.out.println(str5.intern() == str3);// true intern先行检查字符串是否能存在
System.out.println(str5.intern() == str4);// false str4使用+号,相当于新创建了字符串对象关键字
-
transient
-
instanceof
-
volatile
-
synchronized
-
final
-
static
-
const
集合类
Java 集合类图
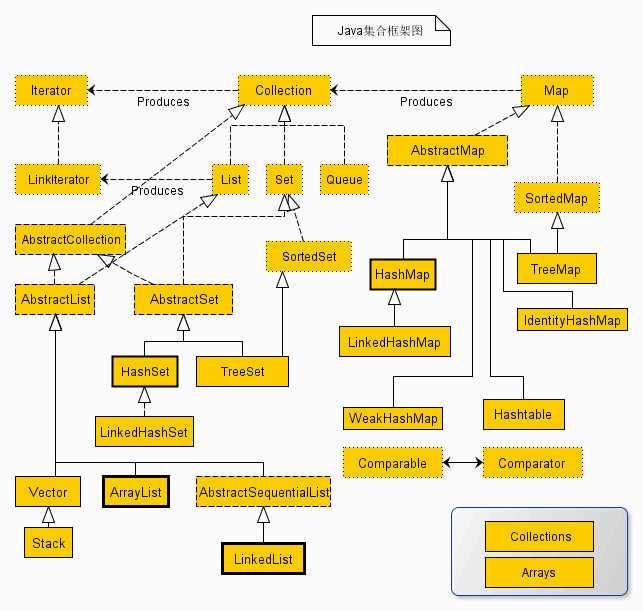
注:图中 LinkIterator 应为 ListIterator
常用集合类的使用
[❗TODO]{.label .danger} 待完善
ArrayList、LinkList 和 Vector 的区别
ArrayList 和 Vector 都是基于数组实现的,而 LinkedList 则是基于双向链表实现的。(查询块,增删慢)
-
Arraylist 的实现原理是采用一个动态对象数组实现的,默认构造方法创建一个空数组,它在第一次添加元素时候,扩展容量为 10,之后的扩充算法:原来数组大小+原来数组的一半(也就是 1.5 倍)。
-
Vector 的实现原理也是采用一个动态对象数组实现的,只不过它的默认构造方法创建一个大小为 10 的对象数组,与 Arraylist 不同的是, 在缺省的情况下,增长原数组长度的一倍(也就是 2 倍)。
-
而对 ArrayList 和 Vector 要进行增删操作的时候,需要移动修改元素后面的所有元素,所以增删的开销比较大,对增删操作的执行效率低。
-
为了防止数组动态扩充过多,建议创建 ArrayList 或者 Vector 时,给定初始容量。
-
Arraylist 多线程中使用不安全,适合在单线程访问时使用,效率较高,而 Vector 线程安全,适合在多线程访问时使用,效率较低。
而对于 LinkedList 来说,增加和删除元素方便,增加或删除一个元素,仅需处理结点间的引用即可。但是查询不方便,需要一个个对比,无法根据下标直接查找。(增删块,查询慢),同时,LinkedList 也是非线程安全的。
扩展搜索:[ArrayList 和 Vector 的扩容机制]{.blue}、[单向链表、双向链表]{.blue} 。
SynchronizedList 和 Vector 的区别
SynchronizedList 和 Vector 最主要的区别:
-
SynchronizedList 有很好的扩展和兼容功能。他可以将所有的 List 的子类转成线程安全的类。
-
使用 SynchronizedList 的时候,进行遍历时要手动进行同步处理。
-
SynchronizedList 可以指定锁定的对象。
HashMap、HashTable、ConcurrentHashMap 区别
-
HashTable 中的方法是同步的,而 HashMap 中的方法在默认情况下是非同步的。在多线程并发的环境下,可以直接使用 HashTable,但是要使用 HashMap 的话就要自己增加同步处理了。
-
在继承关系上,HashTable 是基于陈旧的 Dictionary 类继承来的。 HashMap 继承的抽象类 AbstractMap 实现了 Map 接口。
-
HashTable 中,key 和 value 都不允许出现 null 值,否则会抛出 NullPointerException 异常。 HashMap 中,null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null。
-
在扩容机制上,HashTable 中的 hash 数组初始大小是 11,增加的方式是 old*2+1。HashMap 中 hash 数组的默认大小是 16,而且一定是 2 的指数。
-
HashTable 直接使用对象的 hashCode。 HashMap 重新计算 hash 值。
-
Hashtable、HashMap 都使用了 Iterator。而由于历史原因,Hashtable 还使用了 Enumeration 的方式 。 HashMap 实现 Iterator,支持 fast-fail,Hashtable 的 Iterator 遍历支持 fast-fail,用 Enumeration 不支持 fast-fail。
HashMap 和 ConcurrentHashMap 的区别?
ConcurrentHashMap 和 HashMap 的实现方式不一样,虽然都是使用桶数组实现的,但是还是有区别,ConcurrentHashMap 对桶数组进行了分段,而 HashMap 并没有。
ConcurrentHashMap 在每一个分段上都用锁进行了保护。HashMap 没有锁机制。所以,前者线程安全的,后者不是线程安全的。
Set 和 List 的区别
List,Set 都是继承自 Collection 接口。都是用来存储一组相同类型的元素的。
List 特点:元素有放入顺序,元素可重复 。
Set 特点:元素无放入顺序,元素不可重复。
Set 如何保证元素不重复
在 Java 的 Set 体系中,根据实现方式不同主要分为两大类。HashSet 和 TreeSet。
-
TreeSet 是二叉树实现的,Treeset 中的数据是自动排好序的,不允许放入 null 值
-
HashSet 是哈希表实现的,HashSet 中的数据是无序的,可以放入 null,但只能放入一个 null,两者中的值都不能重复,就如数据库中唯一约束。
在 HashSet 中,基本的操作都是有 HashMap 底层实现的,因为 HashSet 底层是用 HashMap 存储数据的。当向 HashSet 中添加元素的时候,首先计算元素的 hashcode 值,然后通过扰动计算和按位与的方式计算出这个元素的存储位置,如果这个位置位空,就将元素添加进去;如果不为空,则用 equals 方法比较元素是否相等,相等就不添加,否则找一个空位添加。
TreeSet 的底层是 TreeMap 的 keySet(),而 TreeMap 是基于红黑树实现的,红黑树是一种平衡二叉查找树,它能保证任何一个节点的左右子树的高度差不会超过较矮的那棵的一倍。
TreeMap 是按 key 排序的,元素在插入 TreeSet 时 compareTo()方法要被调用,所以 TreeSet 中的元素要实现 Comparable 接口。TreeSet 作为一种 Set,它不允许出现重复元素。TreeSet 是用 compareTo()来判断重复元素的。
Java8 中 stream 相关用法
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API 可以极大提高 Java 程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流,流在管道中传输,并且可以在管道的节点上进行处理,比如筛选,排序,聚合等。
Stream 有以下特性及优点:
-
无存储。Stream 不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java 容器或 I/O channel 等。
-
为函数式编程而生。对 Stream 的任何修改都不会修改背后的数据源,比如对 Stream 执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新 Stream。
-
惰式执行。Stream 上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
-
可消费性。Stream 只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
和以前的 Collection 操作不同, Stream 操作还有两个基础的特征:
-
Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
-
内部迭代: 以前对集合遍历都是通过 Iterator 或者 For-Each 的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream 提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
Stream 用法示例:
public class Java8Tester {
public static void main(String args[]) {
System.out.println("使用 Java 7: ");
// 计算空字符串
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
System.out.println("列表: " + strings);
long count = getCountEmptyStringUsingJava7(strings);
System.out.println("空字符数量为: " + count);
count = getCountLength3UsingJava7(strings);
System.out.println("字符串长度为 3 的数量为: " + count);
// 删除空字符串
List<String> filtered = deleteEmptyStringsUsingJava7(strings);
System.out.println("筛选后的列表: " + filtered);
// 删除空字符串,并使用逗号把它们合并起来
String mergedString = getMergedStringUsingJava7(strings, ", ");
System.out.println("合并字符串: " + mergedString);
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
// 获取列表元素平方数
List<Integer> squaresList = getSquares(numbers);
System.out.println("平方数列表: " + squaresList);
List<Integer> integers = Arrays.asList(1, 2, 13, 4, 15, 6, 17, 8, 19);
System.out.println("列表: " + integers);
System.out.println("列表中最大的数 : " + getMax(integers));
System.out.println("列表中最小的数 : " + getMin(integers));
System.out.println("所有数之和 : " + getSum(integers));
System.out.println("平均数 : " + getAverage(integers));
System.out.println("随机数: ");
// 输出10个随机数
Random random = new Random();
for (int i = 0; i < 10; i++) {
System.out.println(random.nextInt());
}
System.out.println("使用 Java 8: ");
System.out.println("列表: " + strings);
count = strings.stream().filter(string -> string.isEmpty()).count();
System.out.println("空字符串数量为: " + count);
count = strings.stream().filter(string -> string.length() == 3).count();
System.out.println("字符串长度为 3 的数量为: " + count);
filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());
System.out.println("筛选后的列表: " + filtered);
mergedString = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.joining(", "));
System.out.println("合并字符串: " + mergedString);
squaresList = numbers.stream().map(i -> i * i).distinct().collect(Collectors.toList());
System.out.println("Squares List: " + squaresList);
System.out.println("列表: " + integers);
IntSummaryStatistics stats = integers.stream().mapToInt((x) -> x).summaryStatistics();
System.out.println("列表中最大的数 : " + stats.getMax());
System.out.println("列表中最小的数 : " + stats.getMin());
System.out.println("所有数之和 : " + stats.getSum());
System.out.println("平均数 : " + stats.getAverage());
System.out.println("随机数: ");
random.ints().limit(10).sorted().forEach(System.out::println);
// 并行处理
count = strings.parallelStream().filter(string -> string.isEmpty()).count();
System.out.println("空字符串的数量为: " + count);
}
private static int getCountEmptyStringUsingJava7(List<String> strings) {
int count = 0;
for (String string : strings) {
if (string.isEmpty()) {
count++;
}
}
return count;
}
private static int getCountLength3UsingJava7(List<String> strings) {
int count = 0;
for (String string : strings) {
if (string.length() == 3) {
count++;
}
}
return count;
}
private static List<String> deleteEmptyStringsUsingJava7(List<String> strings) {
List<String> filteredList = new ArrayList<String>();
for (String string : strings) {
if (!string.isEmpty()) {
filteredList.add(string);
}
}
return filteredList;
}
private static String getMergedStringUsingJava7(List<String> strings, String separator) {
StringBuilder stringBuilder = new StringBuilder();
for (String string : strings) {
if (!string.isEmpty()) {
stringBuilder.append(string);
stringBuilder.append(separator);
}
}
String mergedString = stringBuilder.toString();
return mergedString.substring(0, mergedString.length() - 2);
}
private static List<Integer> getSquares(List<Integer> numbers) {
List<Integer> squaresList = new ArrayList<Integer>();
for (Integer number : numbers) {
Integer square = new Integer(number.intValue() * number.intValue());
if (!squaresList.contains(square)) {
squaresList.add(square);
}
}
return squaresList;
}
private static int getMax(List<Integer> numbers) {
int max = numbers.get(0);
for (int i = 1; i < numbers.size(); i++) {
Integer number = numbers.get(i);
if (number.intValue() > max) {
max = number.intValue();
}
}
return max;
}
private static int getMin(List<Integer> numbers) {
int min = numbers.get(0);
for (int i = 1; i < numbers.size(); i++) {
Integer number = numbers.get(i);
if (number.intValue() < min) {
min = number.intValue();
}
}
return min;
}
private static int getSum(List numbers) {
int sum = (int) (numbers.get(0));
for (int i = 1; i < numbers.size(); i++) {
sum += (int) numbers.get(i);
}
return sum;
}
private static int getAverage(List<Integer> numbers) {
return getSum(numbers) / numbers.size();
}
}apache 集合处理工具类的使用
[❗TODO]{.label .danger} 待完善
Commons Collections 增强了 Java Collections Framework。它提供了几个功能,使收集处理变得容易。它提供了许多新的接口,实现和实用程序。Commons Collections 的主要功能如下:
-
Bag - Bag 界面简化了每个对象具有多个副本的集合。
-
BidiMap - BidiMap 接口提供双向映射,可用于使用值使用键或键查找值。
-
MapIterator - MapIterator 接口提供简单而容易的迭代迭代。
-
Transforming Decorators - 转换装饰器可以在将集合添加到集合时更改集合的每个对象。
-
Composite Collections - 在需要统一处理多个集合的情况下使用复合集合。
-
Ordered Map - 有序地图保留添加元素的顺序。
-
Ordered Set - 有序集保留了添加元素的顺序。
-
Reference map - 参考图允许在密切控制下对键/值进行垃圾收集。
-
Comparator implementations - 可以使用许多 Comparator 实现。
-
Iterator implementations - 许多 Iterator 实现都可用。
-
Adapter Classes - 适配器类可用于将数组和枚举转换为集合。
-
Utilities - 实用程序可用于测试测试或创建集合的典型集合论属性,例如 union,intersection。 支持关闭。
HashMap 在 JDK1.7 和 JDK1.8 中的差异
-
底层结构不同
JDK1.7 中的 HashMap 结构基于「数组 + 链表」实现。而 JDK1.8 中的 HashMap 结构则是基于「数组 + 链表/红黑色」实现(当链表数大于 8 时,自动转换为红黑树)。
JDK1.8 的设计优势在于:避免了 HashMap 中单条链表过长而影响查询效率。 -
Hash 值计算方式不同
-
插入数据方式不同
JDK1.7 插入数据时采用头插法,即将原位置数据后移,再将数据插入该位置,而 JDK1.8 则采用尾插法,直接将数据插入到链表尾部或红黑树中,这样有效地解决了头插法在多线程中造成死循环的问题。
-
扩容后存储位置的计算方式不同
扩展参考:https://blog.csdn.net/cy973071263/article/details/126390401
Collection 和 Collections 的区别
-
java.util.Collection是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。Collection 接口的意义是为各种具体的集合提供了最大化的统一操作方式。 -
java.util.Collections是一个包装类。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于 Java 的 Collection 框架。
Arrays.asList 获得的 List 使用时需注意什么
-
asList 得到的只是一个 Arrays 的内部类,一个原来数组的视图 List,因此如果对它进行增删操作会报错。
这是因为 Arrays.asList() 方法返回的 ArrayList 不是 java.util 包下的,而是 java.util.Arrays.ArrayList 。这个内部类没有实现 add()、remove()方法,而是直接使用它的父类 AbstractList 的相应方法。而这个方法中相关的 set,add 和 remove 方法均返回
throw new UnsupportedOperationException();。 -
用 ArrayList 的构造器可以将其转变成真正的 ArrayList。
Enumeration 和 Iterator 的区别
-
函数接口不同
Enumeration 只有 2 个函数接口。通过 Enumeration,我们只能读取集合的数据,而不能对数据进行修改。
Iterator 只有 3 个函数接口。Iterator 除了能读取集合的数据之外,也能数据进行删除操作。
-
Iterator 支持 fail-fast 机制,而 Enumeration 不支持。
Enumeration 是 JDK 1.0 添加的接口。使用到它的函数包括 Vector、Hashtable 等类,这些类都是 JDK 1.0 中加入的,Enumeration 存在的目的就是为它们提供遍历接口。Enumeration 本身并没有支持同步,而在 Vector、Hashtable 实现 Enumeration 时,添加了同步。
而 Iterator 是 JDK 1.2 才添加的接口,它也是为了 HashMap、ArrayList 等集合提供遍历接口。Iterator 是支持 fail-fast 机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。
注意:Enumeration 迭代器只能遍历 Vector、Hashtable 这种古老的集合,因此通常不要使用它,除非在某些极端情况下,不得不使用 Enumeration,否则都应该选择 Iterator 迭代器。
fail-fast 和 fail-safe
fail-fast
在系统设计中,快速失效系统是一种可以立即报告任何可能表明故障情况的系统。快速失效系统通常设计用于停止正常操作,而不是试图继续可能存在缺陷的过程。这种设计通常会在操作中的多个点检查系统的状态,因此可以及早检测到任何故障。快速失效模块的职责是检测错误,然后让系统的下一个最高级别处理错误。
fail-fast 机制可以预先识别出一些错误情况,一方面可以避免执行复杂的其他代码,另外一方面,这种异常情况被识别之后也可以针对性的做一些单独处理。
但值得注意的是,Java 的集合类中运用了 fail-fast 机制进行设计,一旦使用不当,触发 fail-fast 机制设计的代码,就会发生非预期情况。
我们通常说的 Java 中的 fail-fast 机制,默认指的是 Java 集合的一种错误检测机制。当多个线程对部分集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制,这个时候就会抛出 ConcurrentModificationException。如在 foreach 循环中对某些集合元素进行元素进行 remove/add 操作。
为什么在 foreach 时进行添加或移除会抛出异常?
foreach 使用了增强 for 循环,而在增强 for 循环中,集合遍历是通过 iterator 进行的,但是元素的 add/remove 却是直接使用的集合类自己的方法。这就导致 iterator 在遍历的时候,会发现有一个元素在自己不知不觉的情况下就被删除/添加了,就会抛出一个 ConcurrentModificationException 异常,用来提示用户,可能发生了并发修改!但实际上这里并没有真的发生并发,只是 Iterator 使用了 fail-fast 的保护机制,只要他发现有某一次修改是未经过自己进行的,那么就会抛出异常。
fail-safe
为了避免触发 fail-fast 机制,导致异常,我们可以使用 Java 中提供的一些采用了 fail-safe 机制的集合类。这样的集合容器在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
java.util.concurrent 包下的容器都是 fail-safe 的,可以在多线程下并发使用,并发修改。同时也可以在 foreach 中进行 add/remove 。fail-safe 集合的所有对集合的修改都是先拷贝一份副本,然后在副本集合上进行的,并不是直接对原集合进行修改。并且这些修改方法,如 add/remove 都是通过加锁来控制并发的。
但是,虽然基于拷贝内容的优点是避免了 ConcurrentModificationException,但同样地,迭代器并不能访问到修改后的内容。
CopyOnWriteArrayList 中 add/remove 等写方法是需要加锁的,目的是为了避免 Copy 出 N 个副本出来,导致并发写。但是,CopyOnWriteArrayList 中的读方法是没有加锁的。这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,当然,这里读到的数据可能不是最新的。因为写时复制的思想是通过延时更新的策略来实现数据的最终一致性的,并非强一致性。
但对于在循环中进行 add/remove 操作时,我们可以使用普通的 for 循环,因为普通 for 循环并没有用到 Iterator 的遍历,所以压根就没有进行 fail-fast 的检验。
Copy-On-Write
Copy-On-Write 简称 COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容 Copy 出去形成一个新的内容然后再改,这是一种延时懒惰策略。
CopyOnWrite 容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
所以 CopyOnWrite 容器是一种读写分离的思想,读和写不同的容器。而 Vector 在读写的时候使用同一个容器,读写互斥,同时只能做一件事儿。
CopyOnWriteArrayList、ConcurrentSkipListMap
从 JDK1.5 开始 Java 并发包里提供了两个使用 CopyOnWrite 机制实现的并发容器,它们是 CopyOnWriteArrayList 和 CopyOnWriteArraySet。CopyOnWrite 容器非常有用,可以在非常多的并发场景中使用到。
CopyOnWriteArrayList
CopyOnWriteArrayList 的整个 add 操作都是在锁的保护下进行的。也就是说 add 方法是线程安全的。CopyOnWrite 并发容器常用于读多写少的并发场景。
和 ArrayList 不同的是,CopyOnWriteArrayList 具有以下特性:
-
支持高效率并发且是线程安全的
-
因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大
-
迭代器支持 hasNext(), next()等不可变操作,但不支持可变 remove()等操作
-
使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
ConcurrentSkipListMap
ConcurrentSkipListMap 是一个内部使用跳表,并且支持排序和并发的一个 Map,是线程安全的。(一般很少会被用到,也是一个比较偏门的数据结构)
ConcurrentSkipListMap 和 ConcurrentHashMap 的主要区别:
-
底层实现方式不同。ConcurrentSkipListMap 底层基于跳表。ConcurrentHashMap 底层基于 Hash 桶和红黑树。
-
ConcurrentHashMap 不支持排序。ConcurrentSkipListMap 支持排序。
枚举
枚举的用法
在 Java 枚举出现之前,表示枚举类型的通常模式是声明一组 int 常量来表示。这种方法在编译时,无法校验该类型的合法性,并且在获取枚举值时,可读性差。因此,从 Java1.5 发行版本开始,就提出了枚举类型,作为替代的解决方案,可以避免int和String枚举模式的缺点,并提供了许多额外的好处。
枚举类型(enum type)是指由一组固定的常量组成合法的类型。Java中由关键字enum来定义一个枚举类型。
public enum Color {
RED, GREEN, BLANK, YELLOW;
}枚举的实现
枚举类本质上是一个继承自 Enum 的类,并且使用关键字 final 进行修饰。当我们使用 enmu 来定义一个枚举类型的时候,编译器会自动帮我们创建一个 final 类型的类继承 Enum 类,所以枚举类型不能被继承。
Enum 类
我们使用 enum 定义的枚举,其实现方式就是通过继承 Enum 类实现的。当我们使用 enmu 来定义一个枚举类型的时候,编译器会自动帮我们创建一个 final 类型的类继承 Enum 类,所以枚举类型不能被继承。
java.lang.Enum 类的定义如下:
package java.lang;
public abstract class Enum<E extends Enum<E>> implements Constable, Comparable<E>, Serializable {
private final String name;
private final int ordinal;
}Java 枚举如何比较
java 枚举值在比较时使用 == 和 equals 方法没有区别,两个随便用都是一样的效果。因为枚举 Enum 类的 equals 方法默认实现就是通过 == 来比较的;
类似的 Enum 的 compareTo 方法比较的是 Enum 的 ordinal 顺序大小;
类似的还有 Enum 的 name 方法和 toString 方法一样都返回的是 Enum 的 name 值。
switch 对枚举的支持
Java 1.7 之前 switch 参数可用类型为 short、byte、int、char,枚举类型之所以能使用其实是编译器层面实现的
编译器会将枚举 switch 转换为类似下面的形式:
switch(s.ordinal()) {
case Status.START.ordinal();
}所以其实质还是 int 参数类型。
枚举的序列化和枚举实现单例
在 JDK 源码的 Class 类中,有一个类型为 Map 的 enumConstantDirectory 的属性。Java 中的每一个类完成加载后都会产生一个 Class 实例保存到堆中,作为该类方法区数据的入口,而枚举在完成加载后也会产生一个对应的 Class 实例,并且,在该实例的 enumConstantDirectory 属性中,保存了所有枚举值的实例。
而所有枚举类都自动继承了 java.ang.Enum 类,该类的静态方法 valueOf 实际上就是从 enumConstantDirectory 中通过 key 获取返回枚举的实例。枚举类在进行序列化时,将会保存这个 key 值,而在进行反序列化时则使用 valueOf 方法通过 name 在 enumConstantDirectory 获取枚举的实例返回。这样,枚举的反序列化就不会产生新的实例。
也正是由于枚举在进行反序列化时不会产生新的实例,而且也无法通过反射创建对象,因此,枚举是实现单例的最好方式。
public class Singleton {
private Singleton () {}
public static enum SingletonEnum {
SINGLETON_ENUM;
private Singleton instance = null;
SingletonEnum () {
instance = new Singleton();
}
public Singleton getInstance() {
return instance;
}
}
public static void main(String[] args) {
Singleton s1 = SingletonEnum.SINGLETON_ENUM.getInstance();
Singleton s2 = SingletonEnum.SINGLETON_ENUM.getInstance();
System.out.println(s1 == s2);// true
}
}枚举的线程安全性问题
编译器会将我们创建的枚举类中的属性及方法声明为 static 修饰,而当一个 Java 类第一次被真正使用到的时候静态资源被初始化、Java 类的加载和初始化过程都是线程安全的。所以,创建一个 enum 类型是线程安全的。
IO
Bit 是最小的二进制单位 ,是计算机的操作部分。取值 0 或者 1
Byte(字节)是计算机操作数据的最小单位由 8 位 bit 组成 取值(-128~127)
Char(字符)是用户的可读写的最小单位,在 Java 里面由 16 位 bit 组成 取值(0~65535)
字符流、字节流
字节流,用于操作 byte(字节)类型数据,主要操作类是 OutputStream、InputStream 的子类;不用缓冲区,直接对文件本身操作。
字符流,用于操作 char(字符)字符类型数据,主要操作类是 Reader、Writer 的子类;使用缓冲区缓冲字符,不关闭流就不会输出任何内容。
整个 IO 包实际上分为字节流和字符流,但是除了这两个流之外,还存在一组字节流-字符流的转换类。
OutputStreamWriter:是 Writer 的子类,将输出的字符流变为字节流,即将一个字符流的输出对象变为字节流输出对象。
InputStreamReader:是 Reader 的子类,将输入的字节流变为字符流,即将一个字节流的输入对象变为字符流的输入对象。
输入流、输出流
输入、输出以存储数据的介质作为参照物,如果是把对象读入到介质中,这就是输入。从介质中向外读数据,这就是输出。所以,输入流是把数据写入存储介质的。输出流是从存储介质中把数据读取出来。
同步、异步、阻塞、非阻塞
同步和异步是针对应用程序和内核交互而言的,也可理解为 被调用者(系统) ,如果是同步,在被调用时会立即执行要做的事。如果是异步,在被调用时不保证会立即执行要做的事,但是保证会去做,而做完之后再通知调用者。
阻塞和非阻塞是针对于进程在访问数据的时候,也可理解为 调用者(程序) ,如果是阻塞,发出调用后,要一直等待返回结果。如果是非阻塞,在发出调用后不需要等待,可以去做自己的事情。
Linux 5 种 IO 模型
在理解 5 种 I/O 模型前,我们需要先明确一点,不管是网络 IO 还是磁盘 IO,对于读操作而言,都是等到网络的某个数据分组到达后(即数据准备阶段),将数据拷贝到内核空间的缓冲区中,再从内核空间拷贝到用户空间的缓冲区。
基于这一点,这里我们通过假设一个点餐的生活场景来理解 5 种 I/O 模型,如下图所示:
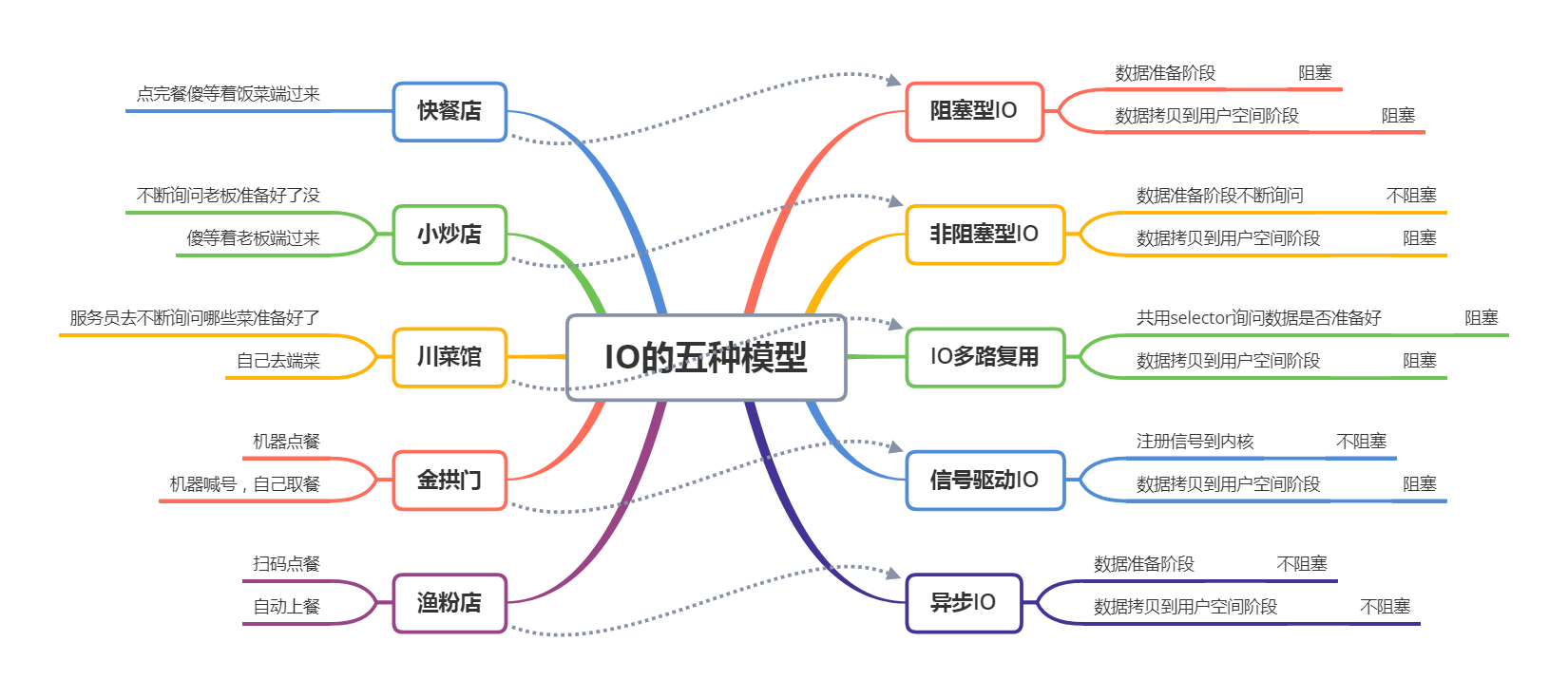
BIO、NIO 和 AIO 的区别、用法和原理
-
BIO(Blocking I/O)
同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。BIO 适用于连接数目比较小且固定的架构,对服务器资源要求高,并发局限于应用中。
-
NIO(New I/O)
同步非阻塞 I/O 模式,它是基于事件驱动思想来完成的,其服务器实现模式为一个请求一个通道,即客户端发送的连接请求都会注册到多路复用器{.dot}上,多路复用器轮询到连接有 I/O 请求时才启动一个线程进行处理。
这种方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程复杂。
NIO 中有以下几种重要角色:
-
缓冲区 Buffer
-
通道 Channel
-
多路复用器 Selector
-
-
AIO(Asynchronous I/O)
异步非阻塞 I/O 模式,在进行读写操作时,只须直接调用 API 的读写方法即可。一个有效请求对应一个线程,客户端的 IO 请求都是 OS 先完成了再通知服务器应用去启动线程进行处理。
Netty
Netty 是一个非阻塞 I/O 客户端-服务器框架,主要用于开发 Java 网络应用程序,如协议服务器和客户端。异步事件驱动的网络应用程序框架和工具用于简化网络编程,例如 TCP 和 UDP 套接字服务器。Netty 包括了反应器编程模式的实现。
除了作为异步网络应用程序框架,Netty 还包括了对 HTTP、HTTP2、DNS 及其他协议的支持,涵盖了在 Servlet 容器内运行的能力、对 WebSockets 的支持、与 Google Protocol Buffers 的集成、对 SSL/TLS 的支持以及对用于 SPDY 协议和消息压缩的支持。
主要优点:提供异步的、事件驱动的网络应用程序框架和工具。
详细使用参考官方文档:https://netty.io/wiki/index.html
反射
反射机制指的是程序在运行时能够获取自身的信息。在 Java 中,只要给定类的名字,那么就可以通过反射机制来获得类的所有属性和方法。
主要由以下的类来实现反射机制(这些类都位于 java.lang.reflect 包中):
-
Class 类:代表一个类。
-
Field 类:代表类的成员变量(成员变量也称为类的属性)。
-
Method 类:代表类的方法。
-
Constructor 类:代表类的构造方法。
-
Array 类:提供了动态创建数组,以及访问数组的元素的静态方法。
反射与工厂模式
工厂模式有三种:
-
简单工厂模式
interface Car { void Name(); } class Aodi implements Car { @Override public void Name() { System.out.println("Aodi"); } } class Aotuo implements Car { @Override public void Name() { System.out.println("Aotuo"); } } class Factory { private Factory() { } public static Car getInstance(String className) { if ("Aodi".equalsIgnoreCase(className)) { return new Aodi(); } else if ("Aotuo".equalsIgnoreCase(className)) { return new Aotuo(); } return null; } } public class Test { public static void main(String[] args) throws Exception { Car car = Factory.getInstance("Aodi"); car.Name(); } } -
工厂方法模式
简单工厂模式引入 Java 反射机制后,变为工厂方法模式。
interface Car { void Name(); } class Aodi implements Car { @Override public void Name() { System.out.println("Aodi"); } } class Aotuo implements Car { @Override public void Name() { System.out.println("Aotuo"); } } class Factory { private Factory() { } public static Car getInstance(String className) { Car instance = null; try { instance = (Car) Class.forName(className).getDeclaredConstructor().newInstance(); } catch (Exception e) { e.printStackTrace(); } return instance; } } public class Test { public static void main(String[] args) { Car car = Factory.getInstance("sample.Aodi"); car.Name(); } } -
抽象工厂模式
// 抽象产品 interface Car { void Name(); } // 具体产品 class Aodi implements Car { @Override public void Name() { System.out.println("Aodi"); } } // 具体产品 class Aotuo implements Car { @Override public void Name() { System.out.println("Aotuo"); } } // 抽象工厂 interface CarFactory { Car getInstance(); } // 具体工厂 class AodiFactory implements CarFactory { @Override public Car getInstance() { return new Aodi(); } } // 具体工厂 class AotuoFactory implements CarFactory { @Override public Car getInstance() { return new Aotuo(); } } public class Test { public static void main(String[] args) { CarFactory carFactory = new AodiFactory(); Car audi = carFactory.getInstance(); audi.Name(); } }
其实, Spring IoC 就是工厂模式 + Java 的反射机制的实际应用。
反射有什么用
-
在运行时判断任意一个对象所属的类。
-
在运行时判断任意一个类所具有的成员变量和方法。
-
在运行时任意调用一个对象的方法。
-
在运行时构造任意一个类的对象。
Class 类
Java 的 Class 类是 java 反射机制的基础,通过 Class 类我们可以获得关于一个类的相关信息。
Java.lang.Class 是一个比较特殊的类,它用于封装被装入到 JVM 中的类(包括类和接口)的信息。当一个类或接口被装入的 JVM 时便会产生一个与之关联的 java.lang.Class 对象,可以通过这个 Class 对象对被装入类的详细信息进行访问。
虚拟机为每种类型管理一个独一无二的 Class 对象。也就是说,每个类(型)都有一个 Class 对象。运行程序时,Java 虚拟机(JVM)首先检查是否所要加载的类对应的 Class 对象是否已经加载。如果没有加载,JVM 就会根据类名查找.class 文件,并将其 Class 对象载入。
如果精力允许,可以看看
java.lang.reflect包下内的源码。
动态代理
代理模式为其他对象提供了一个代理,以控制对某个对象访问,代理类为被代理类预处理消息、过滤消息并在此之后将消息转发给被代理类,之后还能进行消息的后置处理。代理类和被代理类通常会存在关联关系(即持有被代理对象的引用),代理类本身不实现服务,而是通过调用被代理类中的方法来提供服务。
Java 三种代理模式
静态代理
静态代理示例:
public class Test {
interface HelloInterface {
void sayHello();
}
static class Hello implements HelloInterface {
@Override
public void sayHello() {
System.out.println("Hello Chinmoku!");
}
}
static class HelloProxy implements HelloInterface {
private HelloInterface helloInterface = new Hello();
@Override
public void sayHello() {
System.out.println("Before invoke sayHello");
helloInterface.sayHello();
System.out.println("After invoke sayHello");
}
}
public static void main(String[] args) {
HelloProxy helloProxy = new HelloProxy();
helloProxy.sayHello();
}
}
// 执行结果:
// Before invoke sayHello
// Hello Chinmoku!
// After invoke sayHello静态代理需要代理对象和目标对象实现一样的接口,其优点在于,它可以在不修改目标对象的前提下扩展目标对象的功能。
而由于代理对象要实现与目标对象一致的接口,这会产生过多的代理类,另一方面,一旦接口的方法进行了更新,目标对象与代理对象都要进行修改,简单来说,静态代理的缺点在于冗余和不易维护。
动态代理
动态代理利用了 JDK API ,动态地在内存中构建代理对象,从而实现对目标对象的代理功能。因此动态代理又被称为 JDK 代理或接口代理。
静态代理与动态代理的区别主要在于:
-
静态代理在编译时就已经实现,编译完成后代理类是一个实际的 class 文件。
-
动态代理是在运行时动态生成的,即编译完成后没有实际的 class 文件,而是在运行时动态生成类字节码,并加载到 JVM 中。
动态代理对象不需要实现接口,但是要求目标对象必须实现接口,否则不能使用动态代理。
动态代理示例:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class Test {
interface HelloInterface {
void sayHello();
}
static class Hello implements HelloInterface {
@Override
public void sayHello() {
System.out.println("Hello Chinmoku!");
}
}
static class DynamicProxy implements InvocationHandler {
private Object object;
public DynamicProxy(Object obj) {
this.object = obj;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("Before invoke sayHello");
method.invoke(object, args);
System.out.println("After invoke sayHello");
return null;
}
}
public static void main(String[] args) {
HelloInterface hello = new Hello();
InvocationHandler h = new DynamicProxy(hello);
HelloInterface proxy = (HelloInterface) Proxy.newProxyInstance(HelloInterface.class.getClassLoader(), new Class[]{HelloInterface.class}, h);
proxy.sayHello();
}
}
// 执行结果:
// Before invoke sayHello
// Hello Chinmoku!
// After invoke sayHelloCglib 代理
JDK 代理要求被代理对象是一个接口的实现类,如果被代理对象没有实现任何接口,就可以通过 Cglib 进行代理。Cglib 是针对类来实现代理的,他的原理是对指定的目标生成一个子类,并覆盖其中的方法实现增强。但由于其使用继承方式实现,因此,它无法对 final 关键词修饰的类进行代理。
Cglib 既可以为实现接口的类进行代理,也可以为没有实现接口的类进行代理。
Cglib 代理示例:
import org.springframework.cglib.proxy.Enhancer;
import org.springframework.cglib.proxy.MethodInterceptor;
import org.springframework.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class Test {
static class Hello {
public void sayHello() {
System.out.println("Hello Chinmoku!");
}
}
static class HelloServiceCglibProxy implements MethodInterceptor {
private Object target;
public HelloServiceCglibProxy(Object target) {
this.target = target;
}
public Object getProxyInstance() {
Enhancer en = new Enhancer();
en.setSuperclass(target.getClass());
en.setCallback(this);
return en.create();
}
@Override
public Object intercept(Object object, Method method, Object[] arg2, MethodProxy proxy) throws Throwable {
System.out.println("Before invoke sayHello");
Object obj = method.invoke(target);
System.out.println("After invoke sayHello");
return obj;
}
}
public static void main(String[] args) {
Hello target = new Hello();
HelloServiceCglibProxy proxyFactory = new HelloServiceCglibProxy(target);
Hello proxy = (Hello)proxyFactory.getProxyInstance();
proxy.sayHello();
}
}
// 执行结果:
// Before invoke sayHello
// Hello Chinmoku!
// After invoke sayHello动态代理和反射的关系
动态代理实现了 java.lang.reflect.InvocationHandler 接口,而 java.lang.reflect.Proxy 作为其实例,它提供了一个 newProxyInstance() 方法,通过这个方法,程序可以将需要被代理的对象信息传递到 InvocationHandler 这个处理器上。
反射的主要作用是:
-
动态地创建类的实例,并将类绑定到现有的对象中,或从现有的对象中获取类型。
-
应用程序需要在运行时从某个特定的程序集中载入一个特定的类。
而动态代理则是根据对象在内存中加载的 Class 类创建运行时类对象,从而调用代理类方法和属性。简单来说,动态代理是基于 Java 反射机制实现的。
AOP
Java 是一种面向对象的编程语言,它用对象、属性和行为来描述一个简单的事物,并引入了封装、继承、多态的概念,使其具备了描述复杂事物的能力。但当它需要为一些分散对象的公共行为进行描述时,就会显得相当乏力(不是不能),因此就出现了面向切面编程(AOP)的思想,它使用一种被称为横切(cross-cutting)的技术,它将一系列(纵向发展的)行为(横向)剖解开来,并为其织入代理对象,以达到为这些复杂的行为提取出公共行为的目的,这种公共行为在 AOP 思想中被称为切面(Aspect),而这种公共行为,往往是与主要行为(即业务逻辑)无关或关联性极低的行为,比如日志记录、权限控制、性能监控、缓存优化、事务管理等。AOP 将这些非业务性而又至关重要的代码提取出来,极大地减少了代码的重复和耦合,并且有利于维护。
需要特别强调的是,AOP 和 OOP 一样,它并不是某种特定的技术,而是一种编程思想,它弥补了 OOP 思想的不足之处,我们可以说 AOP 是 OOP 的补充和完善。
简单来说,动态地将代码切入到类的指定方法、指定位置上的编程思想,就是切面编程。
注意:Spring AOP 是在运行时生成并织入(weave)代理对象的,但并非所有的 AOP 实现方式都是如此,也有的可以在编译期或类加载期织入,比如 AspectJ 。
AOP 相关概念
-
切面(Aspect)
切面由切入点和通知组成,它既包含了横切逻辑的定义,也包括了切入点的定义。
可以简单地认为, 使用 @Aspect 注解的类就是切面。
@Component @Aspect public class LogAspect { } -
目标对象(Target)
目标对象指将要被增强的对象,即包含主业务逻辑的类对象。或者说是被一个或者多个切面所通知的对象。
-
连接点(JoinPoint)
程序执行过程中明确的点,如方法的调用或特定的异常被抛出。连接点由两个信息确定:
-
方法(表示程序执行点,即在哪个目标方法)
-
相对点(表示方位,即目标方法的什么位置,比如调用前,后等)
简单来说,连接点就是被拦截到的程序执行点,因为 Spring 只支持方法类型的连接点,所以在 Spring 中连接点就是被拦截到的方法。
@Before("pointcut()") public void log(JoinPoint joinPoint) { // 这个JoinPoint参数就是连接点 } -
-
切入点(PointCut)
切入点是对连接点进行拦截的条件定义。切入点表达式如何和连接点匹配是 AOP 的核心,Spring 缺省使用 AspectJ 切入点语法。
一般认为,所有的方法都可以认为是连接点,但是我们并不希望在所有的方法上都添加通知,而切入点的作用就是提供一组规则(使用 AspectJ pointcut expression language 来描述)来匹配连接点,给满足规则的连接点添加通知。
@Pointcut("execution(* com.chinmoku.test.aop.service..*(..))") public void pointcut() { } -
通知(Advice)
通知是指拦截到连接点之后要执行的代码,Spring AOP 框架以拦截器来实现通知模型,并维护一个以连接点为中心的拦截器链。
// @Before说明这是一个前置通知,log函数中是要前置执行的代码,JoinPoint是连接点, @Before("pointcut()") public void log(JoinPoint joinPoint) { }通知类型:
-
前置通知
-
环绕通知
-
后置通知
-
异常通知
-
最终通知
-
-
织入(weave)
织入是将切面和业务逻辑对象连接起来, 并创建通知代理的过程。织入可以在编译时,类加载时和运行时完成。在编译时进行织入就是静态代理,而在运行时进行织入则是动态代理。
-
增强器(Advisor)
Advisor 是切面的另外一种实现,能够将通知以更为复杂的方式织入到目标对象中,是将通知包装为更复杂切面的装配器。Advisor 由切入点和 Advice 组成。
序列化
什么是序列化与反序列化?
序列化,简单来说,就是将对象转化成字节序列的过程。用于对象的传输,和持久化。
反序列化则与序列化相反,它是将字节序列转换成对象的过程。
为什么要进行序列化?
当俩个进程进行远程通信时,可以相互发送各种类型的数据,而这些数据都会以二进制的形式在网络上传送。而 Java 进程在进行通信时,则需要将 Java 对象转换为二进制,这种转换的过程,则是序列化的过程,而将其还原则是反序列化的过程。
另外,由于一般 Java 对象的生命周期比 JVM 短,而在实际的开发中,我们需要在 JVM 停止后能够继续持有对象,这个时候就需要用到序列化技术将对象持久到磁盘或数据库。
JDK 中的序列化步骤:
-
创建一个对象输出流,它可以包装一个其它类型的目标输出流,如文件输出流:
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("D:\\object.out")); -
通过对象输出流的
writeObject()方法写对象:outputStream.writeObject(new User("zhangsan", "123456", "male"));
JDK 中的反序列化步骤:
-
创建一个对象输入流,它可以包装一个其它类型输入流,如文件输入流:
ObjectInputStream ois= new ObjectInputStream(new FileInputStream("object.out")); -
通过对象输出流的
readObject()方法读取对象:User user = (User) ois.readObject();
为了正确读取数据,完成反序列化,必须保证向对象输出流写对象的顺序与从对象输入流中读对象的顺序一致。
注:static 和 transient 字段不能被序列化。
序列化底层原理
[❗TODO]{.label .danger} 待完善
serialVersionUID
serialVersionUID 适用于 Java 的序列化机制。简单来说,Java 的序列化机制是通过判断类的 serialVersionUID 来验证版本一致性的。在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是 InvalidCastException 。
serialVersionUID 有两种显示的生成方式:
-
默认的 1L
private static final long serialVersionUID = 1L; -
根据类名、接口名、成员方法及属性等来生成一个 64 位的哈希字段
private static final long serialVersionUID = xxxxL;
当实现 java.io.Serializable 接口的类没有显式地定义一个 serialVersionUID 变量时候,Java 序列化机制会根据编译的 Class 自动生成一个 serialVersionUID 作序列化版本比较用,这种情况下,如果 Class 文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释等等),就算再编译多次,serialVersionUID 也不会变化的。
如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,就需要显式地定义一个名为 serialVersionUID,类型为 long 的变量,不修改这个变量值的序列化实体都可以相互进行串行化和反串行化。
序列化与单例模式
序列化和反序列化会影响破坏单例模式,这是因为反序列化的时候会去反射调用对象的无参构造方法。
解决方法:
只要在 Singleton 类中定义 readResolve 就可以解决序列化和反序列化对单例模式的破坏。
public class Singleton implements Serializable{
private volatile static Singleton singleton;
private Singleton () {}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
private Object readResolve() {
return singleton;
}
}更加详细的解释,可参考:https://www.hollischuang.com/archives/1144
ProtoBuf
ProtoBuf (Google Protocol Buffers)是一种灵活,高效,自动化机制的结构数据序列化方法,可类比 XML ,但是它比 XML 更小、更快、更为简单。你可以定义数据的结构,然后使用 ProtoBuf 生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏根据旧数据结构编译而成并且已部署的程序。
| 对比方面 | XML | JSON | ProtoBuf |
|---|---|---|---|
| 数据结构 | 一般复杂 | 简单 | 比较复杂 |
| 数据存储方式 | 文本 | 文本 | 二进制 |
| 数据存储大小 | 大 | 一般 | 小 |
| 解析效率 | 慢 | 一般 | 快 |
| 跨语言支持 | 非常多 | 多 | 一般 |
| 学习成本 | 比较繁琐 | 简单 | 一般 |
| 开发成本 | 一般 | 低 | 一般 |
ProtoBuf 文件以 .proto 作为后缀名,下面是一个简单的 ProtoBuf 文件内容示例:
syntax = "proto3";
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}为什么说序列化并不安全
因为序列化的对象数据转换为二进制,并且完全可逆。在 RMI 调用时,所有 private 字段的数据都以明文二进制的形式出现在网络的套接字上,
更加深入的理解,可参考:https://www.jianshu.com/p/fa912ce0426f
注解
元注解
元注解,即定义其他注解的注解。元注解有四个:
-
@Target(表示该注解可以用于什么地方)
-
@Retention(表示在什么级别保存该注解信息)
-
@Documented(将此注解包含再 javadoc 中)
-
@Inherited(允许子类继承父类中的注解)
自定义注解
除了元注解,都是自定义注解。通过元注解定义出来的注解。如我们常用的 Override 、Autowire 等。 日常开发中也可以自定义一个注解,这些都是自定义注解。
Java 中常用注解使用
-
@Override 表示当前方法覆盖了父类的方法
-
@Deprecation 表示方法已经过时,方法上有横线,使用时会有警告。
-
@SuppressWarnings 表示关闭一些警告信息(通知 java 编译器忽略特定的编译警告)
-
@SafeVarargs (jdk1.7 更新) :专门为抑制“堆污染”警告提供的。
-
@FunctionalInterface (jdk1.8 更新) :用来指定某个接口必须是函数式接口,否则就会编译出错。
注解与反射的结合
注解与反射结合使用示例:
public class Test {
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD})
@interface MyAnnotation {
int value();
}
static class MyBean {
@MyAnnotation(20)
private int value;
@Override
public String toString() {
return String.valueOf(value);
}
}
public static void main(String[] args) {
try {
Field field = MyBean.class.getDeclaredField("value");// 获取成员变量value
field.setAccessible(true);// 将value设置成可访问的
if (field.isAnnotationPresent(MyAnnotation.class)) {// 判断成员变量是否有注解
MyAnnotation myAnnotation = field.getAnnotation(MyAnnotation.class);// 获取定义在成员变量中的注解MyAnnotation
int value = myAnnotation.value();// 获取定义在MyBean的MyAnnotation里面属性值
MyBean myBean = new MyBean();
field.setInt(myBean, value);// 将注解的值20可以赋给成员变量value
System.out.println(myBean);// 验证结果
}
} catch (Exception e) {
e.printStackTrace();
}
;
}
}Spring 常用注解
-
@Configuration 把一个类作为一个 IoC 容器,它的某个方法头上如果注册了@Bean,就会作为这个 Spring 容器中的 Bean。
-
@Scope 注解 作用域
-
@Lazy(true) 表示延迟初始化
-
@Service 用于标注业务层组件
-
@Controller 用于标注控制层组件@Repository 用于标注数据访问组件,即 DAO 组件。
-
@Component 泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
-
@Scope 用于指定 scope 作用域的(用在类上)
-
@PostConstruct 用于指定初始化方法(用在方法上)
-
@PreDestory 用于指定销毁方法(用在方法上)
-
@DependsOn 定义 Bean 初始化及销毁时的顺序
-
@Primary 自动装配时当出现多个 Bean 候选者时,被注解为@Primary 的 Bean 将作为首选者,否则将抛出异常
-
@Autowired 默认按类型装配,如果我们想使用按名称装配,可以结合@Qualifier 注解一起使用。如下:
-
@Autowired @Qualifier(“personDaoBean”) 存在多个实例配合使用
-
@Resource 默认按名称装配,当找不到与名称匹配的 bean 才会按类型装配。
-
@PostConstruct 初始化注解
-
@PreDestroy 摧毁注解,默认,单例,启动就加载
JMS
关于 JMS 及其实现,这里仅提出梗要,更多详细内容将记录在 Java 高级篇相关文章内。
什么是 Java 消息服务
JMS 即 Java 消息服务(Java Message Server)应用程序接口,它是 Java 平台中关于面向消息中间件(MOM)的 API,用于两个应用程序之间,或分布式系统中发送消息,进行异步通信,Java 消息服务是一个与具体平台无关的 API,绝大多数 MOM 提供商都对 JMS 提供支持。
JMS 消息传送模型
JMS 具有两种通信模式:
-
Point-to-Point Messaging Domain(点对点通信模型)
-
Publish/Subscribe Messaging Domain(发布 / 订阅通信模型)
JMS 编程模型
JMS 编程模型由以下主体构成:
-
ConnectionFactory:连接工厂(创建连接)
-
Connection:连接(创建会话)
-
Session:会话(创建目的地、生产者、消费者、消息)
-
Destination:目的地(消息发送目标)
-
MessageProducer:消息生产者(发送消息)
-
MessageConsumer:消息消费者(消费消息)
-
Message:消息(内容主体)
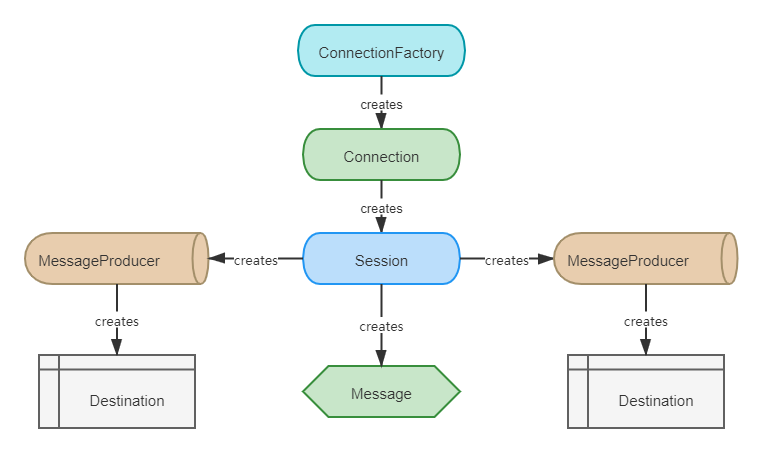
常用的 JMS 实现
-
ActiveMQ
-
RabbitMQ
-
RocketMQ
注意:kafka 不是 JMS 的实现。
JMX
JMX 全称为 Java Management Extensions,它是一个 Java 平台的管理和监控接口。它最常用到的就是对于 JVM 的监测和管理,比如 JVM 内存、CPU 使用率、线程数、垃圾收集情况等等。另外,还可以用作日志级别的动态修改,比如 log4j 就支持 JMX 方式动态修改线上服务的日志级别。最主要的还是被用来做各种监控工具,如 Spring Boot Actuator、JConsole、VisualVM 等。
为了标准化管理和监控,Java 平台使用 JMX 作为管理和监控的标准接口,任何程序,只要按 JMX 规范访问这个接口,就可以获取所有管理与监控信息。
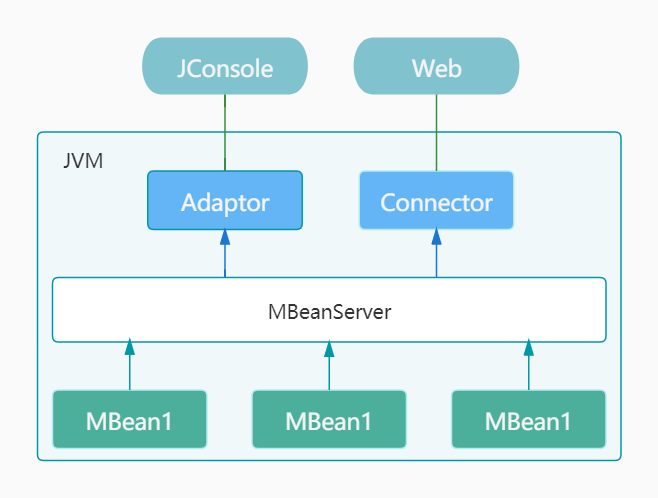
JMX 把所有被管理的资源都称为 MBean(Managed Bean),这些 MBean 全部由 MBeanServer 管理,如果要访问 MBean,可以通过 MBeanServer 对外提供的访问接口,例如通过 RMI 或 HTTP 访问。
使用 JMX 不需要安装任何额外组件,也不需要第三方库,因为 MBeanServer 已经内置在 JavaSE 标准库中了。JavaSE 还提供了一个 jconsole 程序,用于通过 RMI 连接到 MBeanServer,这样就可以管理整个 Java 进程。
JVM 会把自身的各种资源以 MBean 注册到 JMX 中,同时,程序自己的配置、监控信息也可以作为 MBean 注册到 JMX,这样,管理程序就可以直接控制程序暴露的 MBean。
JMX 中 MBean 有 DynamicMBean 和 StandardMBean 两类,前者动态组装一个监控对象,较为复杂,但更为灵活,不需要监控类继承*MBean 接口,后者简单。
应用程序使用 JMX 只需要两步:
-
编写 MBean 提供管理接口和监控数据;
-
注册 MBean(在 Spring 应用中,这一步将自动完成)。
示例:
import javax.management.MBeanServer;
import javax.management.ObjectName;
import java.lang.management.ManagementFactory;
public class HelloJMX implements HelloJMXMBean {
private String name;
@Override
public String getName() {
return name;
}
@Override
public void setName(String name) {
this.name = name;
}
@Override
public void printHello() {
System.out.println("HelloJMX, " + name);
}
@Override
public void printHello(String whoName) {
System.out.println("HelloJMX, it is " + whoName);
}
public static void main(String[] args) throws Exception {
MBeanServer server = ManagementFactory.getPlatformMBeanServer();
ObjectName helloName = new ObjectName("george:name=HelloJMX");
server.registerMBean(new HelloJMX(), helloName);
Thread.sleep(Long.MAX_VALUE);
}
}启动示例程序,然后在终端启动一个 JConsole ,并连接该示例程序的进程,监控窗口如下:
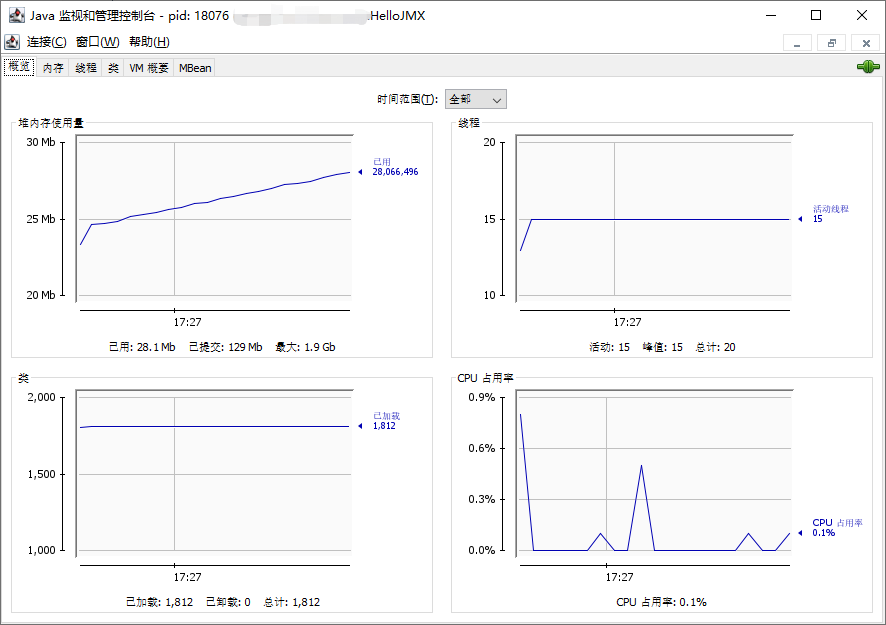
启动 jconsole 方法:在终端执行命令
jconsole即可。
Java 监控相关软件包:
-
java.lang.management.*
-
javax.management.*
更多内容,请阅读:
泛型
Java 泛型(generics)是 JDK 5 中引入的⼀个新特性, 允许在定义类和接口的时候使用类型参数 。
声明的类型参数在使用时用具体的类型来替换。 泛型最主要的应⽤是在 JDK 5 中的新集合类框架中。
泛型最⼤的好处是可以提⾼代码的复用性。 以 List 接口为例,我们可以将 String、Integer 等类型放⼊ List 中,如不用泛型,存放 String 类型要写⼀个 List 接口,存放 Integer 要写另外⼀个 List 接口,泛型可以很好的解决这个问题。
泛型与继承
类型擦除
Java 语言的泛型采用的是擦除法实现的伪泛型,泛型信息(类型变量、参数化类型)编译之后通通被除掉了。使用擦除法的好处就是实现简单、并且能够向后兼容,运行期也能够节省一些类型所占的内存空间。而擦除法的坏处就是,通过这种机制实现的泛型远不如真泛型灵活和强大。Java 选取这种方法是一种折中,因为 Java 最开始的版本是不支持泛型的,为了兼容以前的库而不得不使用擦除法。
泛型类型只有在静态类型检查期间才出现,在此之后,程序中的所有泛型类型都将被擦除,替换成它们非泛型上界。
可以简单理解为:类型擦除即是将 Java 泛型代码转换为普通 Java 代码。
类型擦除的主要过程:
-
将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。
-
移除所有的类型参数。
泛型中的 KTVE?object
-
K 代表 Key 的意思。
-
T 代表一般的任何类。
-
V 代表 Value 的意思,通常与 K 一起配合使用。
-
E 代表 Element 的意思,或者 Exception 异常的意思。
-
? 通配符, 代表某种确定的类型,但是又有不确定性。 比如
<? extends Collection>不确定类型,确定实现了 Collection 接口。能确定上限,或确定下限。 -
object 超类,需要强制类型转换,编译时可能类型不一致导致报错。
限定通配符和非限定通配符
-
<?>被称为非限定通配符,可以用任意类型来替代。 -
<? extends T>被称为有上限的限定通配符,泛型类型必须为 T 或 T 的子类。extends 被称为上界限定符。
-
<? super T>被称为有下限的限定通配符,泛型类型必须为 T 或 T 的父类。super 被称为下界限定符。
List、List<?>和 List<Object>
-
List<Object>和 List 的区别
原始类型 List 和带参数类型
List<Object>之间的主要区别是,在编译时编译器不会对原始类型进行类型安全检查,却会对带参数的类型进行检查。它们之间的第二点区别是,你可以把任何带参数的类型传递给原始类型 List,但却不能把 List 传递给接受List<Object>的方法,因为会产生编译错误。 -
List<Object>和 List<?>的区别
List<?>是一个未知类型的 List,而List<Object>其实是任意类型的 List。你可以把List<String>,List<Integer>赋值给List<?>,却不能把List<String>赋值给List<Object>。
单元测试
单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。对于单元测试中单元的含义,一般来说,要根据实际情况去判定其具体含义,Java 里单元指一个类,图形化的软件中可以指一个窗口或一个菜单等。总的来说,单元就是人为规定的最小的被测功能模块。单元测试是在软件开发过程中要进行的最低级别的测试活动,软件的独立单元将在与程序的其他部分相隔离的情况下进行测试。
quote from 百度百科_单元测试
注:本文对单元测试相关内容归类为了解性知识(但其实这部分知识点应用频率也不算太低,总之,根据个人情况吧),这里仅作简要说明,如果想要了解更多内容,可以查看这一部分推荐的相关链接。
关于单元测试的讨论,可以看这一片知乎帖子:https://www.zhihu.com/question/28729261
JUnit
JUnit 是一个 Java 编程语言的单元测试框架,是截止目前 Java 单元测试领域最流行的框架。
关于 JUnit5 介绍,可以阅读:https://zhuanlan.zhihu.com/p/111706639
Mock
Mock 通常是指,在测试一个对象 A 时,我们构造一些假的对象来模拟与 A 之间的交互,而这些 Mock 对象的行为是我们事先设定且符合预期。通过这些 Mock 对象来测试 A 在正常逻辑,异常逻辑或压力情况下工作是否正常。
引入 Mock 最大的优势在于:Mock 的行为固定,它确保当你访问该 Mock 的某个方法时总是能够获得一个没有任何逻辑的直接就返回的预期结果。
Mockito
Mockio 是一款 Java Mock 测试工具。
关于 Mockio ,可以参考:https://www.cnblogs.com/bodhitree/p/9456515.html
内存数据库(h2)
H2 是一个开源的嵌入式(非嵌入式设备)数据库引擎,它是一个用 Java 开发的类库,可直接嵌入到应用程序中,与应用程序一起打包发布,不受平台限制。
Java H2 数据库连接示例:
-
下载启动
下载地址:http://www.h2database.com/html/download.html
运行脚本文件
h2.bat -
在测试项目中添加依赖
<dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <version>1.4.190</version> </dependency> -
编写测试文件
import org.h2.tools.Server; import java.sql.*; public class H2Demo { private Server server; private String port = "8082"; private String dbDir = "jdbc:h2:tcp://192.168.0.36/~/test"; private String user = "sa"; private String password = ""; public void startServer() { try { System.out.println("正在启动h2..."); server = Server.createTcpServer(new String[]{"-tcpPort", port}).start(); } catch (SQLException e) { System.out.println("启动h2出错:" + e.toString()); e.printStackTrace(); throw new RuntimeException(e); } } public void stopServer() { if (server != null) { System.out.println("正在关闭h2..."); server.stop(); System.out.println("关闭成功."); } } public void useH2() { try { Class.forName("org.h2.Driver"); Connection conn = DriverManager.getConnection(dbDir, user, password); Statement stat = conn.createStatement(); // insert data // stat.execute("CREATE TABLE TEST(NAME VARCHAR)"); stat.execute("INSERT INTO TEST VALUES('Hello World')"); // use data ResultSet result = stat.executeQuery("select name from test "); int i = 1; while (result.next()) { System.out.println(i++ + ":" + result.getString("name")); } result.close(); stat.close(); conn.close(); } catch (Exception e) { e.printStackTrace(); } } public static void main(String[] args) { H2Demo h2 = new H2Demo(); // h2.startServer(); h2.useH2(); // h2.stopServer(); System.out.println("==END=="); } }
正则表达式
正则表达式描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式在线工具:
常用的 Java 工具库
commons.lang
在 org.apache.commons.lang 包中提供了一些有用的包含 static 方法的 Util 类。除了 6 个 Exception 类和 2 个已经 deprecated 的数字类之外,commons.lang 包共包含了 17 个实用的类:
-
ArrayUtils – 用于对数组的操作,如添加、查找、删除、子数组、倒序、元素类型转换等;
-
BitField – 用于操作位元,提供了一些方便而安全的方法;
-
BooleanUtils – 用于操作和转换 boolean 或者 Boolean 及相应的数组;
-
CharEncoding – 包含了 Java 环境支持的字符编码,提供是否支持某种编码的判断;
-
CharRange – 用于设定字符范围并做相应检查;
-
CharSet – 用于设定一组字符作为范围并做相应检查;
-
CharSetUtils – 用于操作 CharSet;
-
CharUtils – 用于操作 char 值和 Character 对象;
-
ClassUtils – 用于对 Java 类的操作,不使用反射;
-
ObjectUtils – 用于操作 Java 对象,提供 null 安全的访问和其他一些功能;
-
RandomStringUtils – 用于生成随机的字符串;
-
SerializationUtils – 用于处理对象序列化,提供比一般 Java 序列化更高级的处理能力;
-
StringEscapeUtils – 用于正确处理转义字符,产生正确的 Java、JavaScript、HTML、XML 和 SQL 代码;
-
StringUtils – 处理 String 的核心类,提供了相当多的功能;
-
SystemUtils – 在 java.lang.System 基础上提供更方便的访问,如用户路径、Java 版本、时区、操作系统等判断;
-
Validate – 提供验证的操作,有点类似 assert 断言;
-
WordUtils – 用于处理单词大小写、换行等。
选择记住一些常用的就行。
guava-libraries
Guava-Libraries 是一套来自 Google 的核心 Java 库,其中包括新的集合类型(如 multimap 和 multiset)、不可变的集合、图库,以及并发、I/O、散列、缓存、基元、字符串等实用工具!它被广泛用于 Google 内部的大多数 Java 项目,也被许多其他公司广泛使用。
Guava 的好处:
-
标准化 - Guava 库是由谷歌托管。
-
高效 - 可靠,快速和有效的扩展 JAVA 标准库
-
优化 - Guava 库经过高度的优化。
-
函数式编程 - 增加 JAVA 功能和处理能力。
-
实用程序 - 提供了经常需要在应用程序开发的许多实用程序类。
-
验证 - 提供标准的故障安全验证机制。
-
最佳实践 - 强调最佳的做法。
本部分内容参考自:https://mulanos.oschina.net/p/guava
netty
[❗TODO]{.label .danger} 待完善
API & SPI
API
API(Application Programming Interface,应用程序接口)是一些预先定义的接口(如函数、HTTP 接口),或指软件系统不同组成部分衔接的约定。用来提供应用程序与开发人员基于某软件或硬件得以访问的一组例程,而又无需访问源码,或理解内部工作机制的细节。
quote from 百度百科_API
SPI
SPI 全称 Service Provider Interface,是 Java 提供的一套用来被第三方实现或者扩展的 API,它可以用来启用框架扩展和替换组件。
如何定义 SPI 及 SPI 的实现原理,参考:https://www.cnblogs.com/oskyhg/p/10800051.html
API 与 SPI 的关系和区别
API 描述的是可以直接使用的方法,达到某种功能的实现。可以简单的理解为服务方暴露自己的服务供客户方调用。比如 Java 的 api 文档,服务方是 JDK,客户方就是 Java 开发人员。API 由开发人员调用。
SPI:服务方提供的不在是提供具体的方法,而是提供对象的接口,客户方需要实现接口, 然后服务方调用客户方的接口实现类,再来实现客户的某种功能。SPI 是框架接口规范,需要框架开发人员实现。
但有时候,API 和 SPI 是分不清的,比如 Connection 接口,Driver 接口等。
异常
异常类型
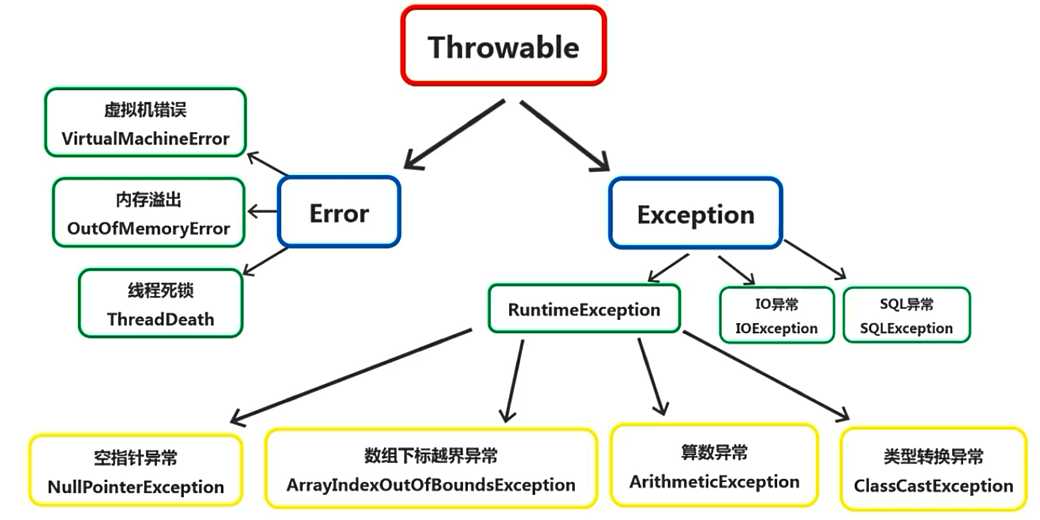
上图简要展示了异常类实现的结构图(并非全部),除此之外,用户也可以自定义异常实现。
-
Throwable 是 Java 异常的根类,所有的异常都是从 Throwable 继承而来的。
-
Throwable 有两个子类,Error 和 Exception。
正确处理异常
代码中的异常处理其实是对可检查异常的处理,主要有以下几个要点:
-
通过
try{}catch(){}语句块处理异常。try { // 可能出现异常的程序代码 } catch(ExceptionName e) { // 捕获异常后的处理 } -
通过
throw/throws抛出异常交由上层处理。除了及时捕获并处理异常外,程序也可以选择暂不处理,而是交给上一层,但必须保证某一层代码要处理该异常。
public class Test { public static void main(String[] args) { try { int result = divide(5, 0); } catch (ArithmeticException e) { System.out.println("---------- method divide() exception ----------"); e.printStackTrace(); } } public static int divide(int numerator, int denominator) throws ArithmeticException { return numerator / denominator; } } -
关键字
finally的使用。finally 关键字用来创建在 try 代码块后面执行的代码块,无论是否发生异常,finally 代码块中的代码总会被执行。在 finally 代码块中,尝用于运行清理类型等收尾善后性质的语句。
tyr { // 可能出现异常的程序代码 } catch(ExceptionName e) { // 捕获异常后的处理 } finally { // 无论是否出现异常,都需要执行的代码 }
自定义异常
在 Java 中要想创建自定义异常,需要继承 Throwable 或者他的子类 Exception。
public class MyBusinessException extends Exception {
// 根据需要重写构造方法及异常处理内部逻辑
public MyBusinessException() {
}
public MyBusinessException(String message) {
super(message);
}
public MyBusinessException(String message, Throwable cause) {
super(message, cause);
}
public MyBusinessException(Throwable cause) {
super(cause);
}
}Error 和 Exception
Error 是程序无法处理的错误,表示运行程序中较严重的问题,它们在应用程序控制和处理范围之外,而且绝大多数是程序运行时不允许出现的状况(是处理不到的),对于设计合理的应用程序,即使确实发生了错误,本质也不应该试图去处理它所引起的异常状况。
Exception 是程序本身可以处理的异常。异常处理通常指针对这种类型异常处理,包括非检查异常(编译器不要求强制处理的异常)和检查异常(编译器要求处理的异常)。
-
Checked Exception
所有可检查的异常都是需要在代码中处理的。它们的发生是可以预测的,正常的一种情况,可以合理的处理。除了 RuntimeException 及其子类以外,都是可检查的异常。
-
Unchecked Exception
RuntimeException 及其子类都是非检查异常。比如 NPE 空指针异常,除数为 0 的算数异常 ArithmeticException 等等,这种异常是运行时发生,无法预先捕捉处理的。
异常链
当 A 方法调用 B 方法时,B 方法抛出异常,而 A 方法期望抛出一个新的异常,这时则会用到异常链进行处理。
异常链示例:
public class ExceptionChainTest {
/**
* paly()抛出【你未遵守公司规定】的异常
* work()调用paly(),捕获【你在玩手机】的异常,并且包装成运行时异常,继续抛出
* main()调用work(),尝试捕获work()方法抛出的异常
*/
public static void main(String[] args) {
ExceptionChainTest ct = new ExceptionChainTest();
try {
ct.work();
} catch (Exception e) {
e.printStackTrace();
}
}
public void work() {
try {
paly();
} catch (BusinessException e) {
RuntimeException newExc = new RuntimeException("----> Please comply with company regulations");
newExc.initCause(e);
throw newExc;
}
}
public void paly() throws BusinessException {
throw new BusinessException("----> Exception: Do not play mobile phones during working hours!");
}
class BusinessException extends Exception {
public BusinessException(String message) {
super(message);
}
}
}try-with-resource
try-with-resource 是 jdk1.7 引入的语法糖,它使得关闭资源操作无需层层嵌套在 finally。要使用 try-with-resource ,必须先实现 AutoCloseable 接口,其中包含了一个无返回值的 close 方法,Java 与第三方许多类和接口,均实现或扩展了 AutoCloseable 接口,因此开发时不需要显示地重复声明实现。
例如一段实现文件拷贝的代码:
public class TryWithResourceTest {
public static void main(String[] args) {
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(new File("in.txt")));
BufferedOutputStream bos = BufferedOutputStream(new FileOutputStream(new File("out.txt")));
) {
int b;
while ((b = bis.read()) != -1) {
bos.write(b);
}
} catch(IOException e) {
e.printStackTrace();
}
}
}注:使用 try-with-resource 时,不需要手动关闭资源。而事实上,它只是一种语法糖,程序在编译时,会还原出真正的包含有 finally 关闭资源相关逻辑的代码块。
finally 和 return 的执行顺序
如果 try 中有 return 语句, 那么 finally 中的代码还是会执⾏。因为 return 表⽰的是要整个⽅法体返回, 所以,finally 中的语句会在 return 之前执⾏。
但是,在 return 前执行的 finally 块中对数据进行更新的效果,会因为引用类型和值类型而不同。
public class Test {
public static void main(String[] args) {
System.out.println(test1());// 0
System.out.println(test2()[0]);// 1
}
public static int test1() {
int a = 0;
try {
return a;
} catch (Exception e) {
e.printStackTrace();
} finally {
a++;// 操作引用类型(无效)
}
return a;
}
public static int[] test2() {
int[] arr = new int[]{0};
try {
return arr;
} finally {
arr[0]++;// 操作值类型(有效)
}
}
}时间处理
时区
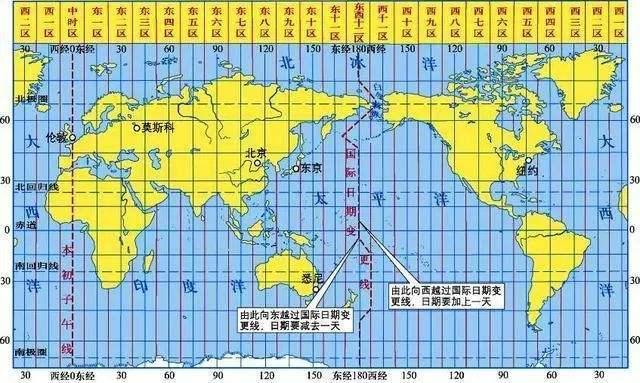
时区划分是高中地理基本知识。如果对时区等基本概念和原理不清楚,可以简单了解下:
参考:https://baijiahao.baidu.com/s?id=1678827052186512442
对于日常开发而言,你只需要简单记住以下几点即可:
-
时区分为十一个东时区、十一个西时区、一个中时区和一个东西十二时区。
-
伦敦处于中时区(本初子午线)。
-
北京时间是东八区时间。
-
两地之间每相距一个时区,时间相差一小时。
冬时令和夏时令
夏令时、冬令时的出现,是为了充分利用夏天的日照,所以时钟要往前拨快一小时,冬天再把表往回拨一小时。其中夏令时从 3 月第二个周日持续到 11 月第一个周日。
-
冬令时: 北京和洛杉矶时差:16 北京和纽约时差:13
-
夏令时: 北京和洛杉矶时差:15 北京和纽约时差:12
时间戳
时间戳(timestamp),一个能表示一份数据在某个特定时间之前已经存在的、 完整的、 可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间。
时间戳是指格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒(北京时间 1970 年 01 月 01 日 08 时 00 分 00 秒)起至现在的总秒数。通俗的讲, 时间戳是一份能够表示一份数据在一个特定时间点已经存在的完整的可验证的数据。
Java 中时间 API
-
java.lang.System
System 类提供的
currentTimeMillis()用来返回当前时间与 1970 年 1 月 1 日 0 时 0 分 0 秒之间以毫秒为单位的时间差。 -
java.util.Date
相关方法当基本用法:
public static void main(String[] args) { Date date = new Date(); System.out.println("date = " + date); Date date2 = new Date(1629791405786L); System.out.println("date2 = " + date2); long time = date.getTime(); System.out.println("time = " + time); date.setTime(time); System.out.println("date = " + date); }注意区分
java.util.Date与java.sql.Date。 -
java.text.SimpleDateFormat
这个类主要用来进行时间格式转换,例如:
public static void main(String[] args) { Date date = new Date(); String strDateFormat = "yyyy-MM-dd HH:mm:ss"; SimpleDateFormat sdf = new SimpleDateFormat(strDateFormat); System.out.println(sdf.format(date)); } -
java.util.Calendar
这是一个日历类。日历字段包含 YEAR、MONTH、DAY_OF_MONTH、HOUR 等,它们都是 Calendar 类的静态常量。
计算时间差示例:
public static void main(String[] args) { LocalDate now = LocalDate.now(); LocalDate localDate = LocalDate.of(2020, 4, 26); Period period = Period.between(localDate, now); System.out.println(period); System.out.println(period.getYears()); System.out.println(period.getMonths()); System.out.println(period.getDays()); System.out.println(period.withYears(2)); }
格林威治时间
格林尼治平时(英语:Greenwich Mean Time,GMT)是指位于英国伦敦郊区的皇家格林尼治天文台当地的平太阳时,因为本初子午线被定义为通过那里的经线。
格林尼治平时基于天文观测本身的缺陷,已经被原子钟报时的协调世界时(UTC)所取代。
一般使用 GMT+8 表示中国的时间,是因为中国位于东八区,时间上比格林威治时间快 8 个小时。
CET,UTC,GMT,CST 几种常见时间的含义和关系
CET 欧洲中部时间(英語:Central European Time,CET)是比世界标准时间(UTC)早一个小时的时区名称之一。它被大部分欧洲国家和部分北非国家采用。冬季时间为 UTC+1,夏季欧洲夏令时为 UTC+2。
UTC 协调世界时,又称世界标准时间或世界协调时间,简称 UTC,从英文“Coordinated Universal Time”/法文“Temps Universel Cordonné”而来。台湾采用 CNS 7648 的《资料元及交换格式–资讯交换–日期及时间的表示法》(与 ISO 8601 类似)称之为世界统一时间。中国大陆采用 ISO 8601-1988 的国标《数据元和交换格式信息交换日期和时间表示法》(GB/T 7408)中称之为国际协调时间。协调世界时是以原子时秒长为基础,在时刻上尽量接近于世界时的一种时间计量系统。
GMT 格林尼治标准时间(旧译格林尼治平均时间或格林威治标准时间;英语:Greenwich Mean Time,GMT)是指位于英国伦敦郊区的皇家格林尼治天文台的标准时间,因为本初子午线被定义在通过那里的经线。
CST 北京时间,China Standard Time,又名中国标准时间,是中国的标准时间。在时区划分上,属东八区,比协调世界时早 8 小时,记为 UTC+8,与中华民国国家标准时间(旧称“中原标准时间”)、香港时间和澳门时间和相同。
关系
CET=UTC/GMT + 1 小时 CST=UTC/GMT +8 小时 CST=CET+9
SimpleDateFormat 的线程安全问题
阿里巴巴 Java 开发手册:SimpleDateFormat 的线程安全问题?
【强制】SimpleDateFormat 是线程不安全的类,一般不要定义为 static 变量,如果定义为 static,必须加锁,或者使用 DateUtils 工具类。
正例:注意线程安全,使用 DateUtils。亦推荐如下处理:
private static final ThreadLoal<DateFormat> df = new ThreadLocal<DateFormat>() {
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd");
}
}引起 SimpleDateFormat 线程安全问题的原因:
SimpleDateFormat 中的 format 方法在执行过程中,会使用一个成员变量 calendar 来保存时间。如果我们在声明 SimpleDateFormat 的时候,使用的是 static 定义的。那么这个 SimpleDateFormat 就是一个共享变量,随之,SimpleDateFormat 中的 calendar 也就可以被多个线程访问到。一个线程在执行 clendar.setTime 方法时,并不能保证不影响到他线程执行 clendar.getTime 。
除了 format 方法以外,SimpleDateFormat 的 parse 方法也有同样的问题。所以,不要把 SimpleDateFormat 作为一个共享变量使用。
解决这个问题的方法有很多,常见有以下几种处理方式:
-
将
SimpleDateFormat作为局部变量使用。 -
为共享变量添加同步锁。
synchronized (simpleDateFormat) { // ... } -
使用 ThreadLocal
见上文提及的《阿里巴巴 Java 开发手册》。
-
使用 DateTimeFormatter
Java8+ 可以使用 DateTimeFormatter 代替 SimpleDateFormat,这是一个线程安全的格式化工具类。
// 解析日期 String dateStr = "2016年10月25日"; DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy年MM月dd日"); LocalDate date = LocalDate.parse(dateStr, formatter); // 日期转换为字符串 LocalDateTime now = LocalDateTime.now(); DateTimeFormatter format = DateTimeFormatter.ofPattern("yyyy年MM月dd日 hh:mm a"); String nowStr = now .format(format); System.out.println(nowStr);
Java 8 中的时间处理
在 Java8 之前的版本中,日期时间 API 存在诸多问题,例如:
-
非线程安全 − java.util.Date 是非线程安全的,所有的日期类都是可变的,这是 Java 日期类最大的问题之一。
-
设计很差 − Java 的日期/时间类的定义不一致。
-
时区处理麻烦 − 日期类并不提供国际化,没有时区支持,因此 Java 引入了 java.util.Calendar 和 java.util.TimeZone 类,但他们同样存在上述所有的问题。
在 Java8 中, 新的时间及⽇期 API 位于 java.time 包中,该包中有如下重要的类:
-
Instant: 时间戳 -
Duration: 持续时间,时间差 -
LocalDate: 只包含⽇期,⽐如: 2021-08-24 -
LocalTime: 只包含时间,比如: 16:37:10 -
LocalDateTime: 包含⽇期和时间,比如:2021-08-24 16:37:10 -
Period: 时间段 -
ZoneOffset: 时区偏移量,⽐如:+8:00 -
ZonedDateTime: 带时区的时间 -
Clock: 时钟,比如获取⽬前美国纽约的时间
新的 java.time 包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。
一些简单的使用方式如下:
// 获取当前时间
LocalDate today = LocalDate.now();
int year = today.getYear();
int month = today.getMonthValue();
int day = today.getDayOfMonth();
System.out.printf("Year : %d Month : %d day : %d t %n", year, month, day);
// 创建指定日期的时间
LocalDate date = LocalDate.of(2021, 10, 01);
// 判断闰年
LocalDate nowDate = LocalDate.now();
boolean leapYear = nowDate.isLeapYear();
// 计算两个时间之间相差的月数和天数
Period period = Period.between(LocalDate.of(2018, 1, 5), LocalDate.of(2018, 2, 5));如何在东八区的计算机上获取美国时间
LocalDateTime now = LocalDateTime.now(ZoneId.of("America/Los_Angeles"));// 区域 / 城市
System.out.println(now);yyyy 和 YYYY 的区别
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
public class Test {
public static void main(String[] args) throws ParseException {
System.out.println(test("yyyy-MM-dd"));;// 小写yyyy - 2020
System.out.println(test("YYYY-MM-dd"));;// 大写YYYY - 2019
}
public static int test(String parten) throws ParseException {
SimpleDateFormat strDateFormat = new SimpleDateFormat(parten);
Date date = strDateFormat.parse("2020-12-24");
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
return calendar.get(Calendar.YEAR);
}
}在 Intellij IDEA 中书写
new SimpleDateFormat("YYYY-MM-dd");时,会进行如下提示:【日期格式化字符串[YYYY-MM-dd]使用错误,应注意使用小写‘y’表示当天所在的年,大写‘Y’代表 week in which year。】
编码方式
ASCII
ASCII( American Standard Code for InformationInterchange, 美国信息交换标准代码) 是基于拉丁字母的⼀套电脑编码系统, 主要⽤于显⽰现代英语和其他西欧语⾔。
它是现今最通⽤的单字节编码系统,并等同于国际标准 ISO/IEC646。但是 ASCII 码只有 256 个字符无法适应非英语语言体系的国家。
Unicode
Unicode 是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。
Unicode 涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。
Unicode 可以表示中文。
Unicode 与 UTF-8
广义的 Unicode 是一个标准,定义了一个字符集以及一系列的编码规则,即 Unicode 字符集和 UTF-8、UTF-16、UTF-32 等等编码规则。
Unicode 是字符集。UTF-8 是编码规则。
Unicode 虽然统一了全世界字符的二进制编码,但没有规定如何存储。不同文字单个字符字节大小并不一致,如果规定统一的编码存储,字节长度较小的字符则会产生大量的内存浪费,因此出现了 Unicode 的多种存储方式。UTF-8(Unicode Tranformation Format)就是 Unicode 的一个使用方式,它使用可变长度字节来储存 Unicode 字符,这样就可以适应不同字节大小的文字存储。
GBK、GB2312、GB18030 区别
三者都是支持中文字符的编码方式,其中最常用的是 GBK。
-
GB2312(1980 年)
16 位字符集。优点:适用于简体中文环境,属于中国国家标准,通行于大陆,新加坡等地也使用此编码;缺点:不兼容繁体中文,其汉字集合过少。
-
GBK(1995 年)
16 位字符集。优点:适用于简繁中文共存的环境,为简体 Windows 所使用,所有字符都可以一对一映射到 unicode2.0 上;缺点:不属于官方标准,和 big5 之间需要转换;很多搜索引擎都不能很好地支持 GBK 汉字。
-
GB18030(2000 年)
32 位字符集,同时收录了藏文、蒙文、维吾尔文等主要的少数民族文字。优点:可以收录所有你能想到的文字和符号,属于中国最新的国家标准;缺点:目前支持它的软件较少。
GBK 是一套国内通用的编码标准。
UTF8、UTF16、UTF32 区别
UTF 是英文 Unicode Transformation Format 的缩写,意为把 Unicode 字符转换为某种格式。UTF 系列编码方案均是由 Unicode 编码方案衍变而来,以适应不同的数据存储或传递,它们都可以完全表示 Unicode 标准中的所有字符。
-
UTF-8
其中大部分汉字采用三个字节编码,少量不常用汉字采用四个字节编码。
-
UTF-16
其中大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。
-
UTF-32
使用四个字节为每个字符编码,它占用空间通常会是其它编码的二到四倍。
URL 编解码
网络标准 RFC 1738 做了硬性规定 :只有字母和数字 0-9a-zA-Z 、一些特殊符号 $-_.+!*'(), 以及某些保留字,才可以不经过编码直接用于 URL;
除此以外的字符是无法在 URL 中展示的,所以,遇到这种字符,如中文,就需要进行编码。所以,把带有特殊字符的 URL 转成可以显示的 URL 过程,称之为 URL 编码。反之,就是解码。
URL 编码可以使用不同的方式,如 escape,URLEncode,encodeURIComponent。
BIG Endian 和 Little Endian
字节序(Endian),也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。
Big Endian 是指低地址端存放高位字节。Little Endian 是指低地址端存放低位字节。
Java 采用 Big Endian 来存储数据,C/C++采用 Little Endian。在网络传输一般采用的网络字节序是 BIG-ENDIAN。
因此当 Java 和 C 语言进行通讯时,C 语言端需要考虑到字节序的转换问题,而 Java 端则无需考虑。
如何解决乱码问题
乱码问题本质上都是由于字符串原本的编码格式与读取时解析用的编码格式不一致导致的。
造成乱码的原因就是因为使用了错误的字符编码去解码字节流,因此当我们在思考任何跟文本显示有关的问题时,需要明确当前使用的字符编码是什么。
语法糖
语法糖(Syntactic Sugar),也称糖衣语法,是由英国计算机学家 Peter.J.Landin 发明的一个术语,指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。简而言之,语法糖让程序更加简洁,有更高的可读性。
解语法糖
语法糖的存在主要是方便开发人员使用,但其实 Java 虚拟机并不支持这些语法糖。这些语法糖在编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。
语法糖
-
switch 支持 String 与枚举
字符串的 switch 是通过
equals()和hashCode()方法来实现的。而枚举则是通过其ordinal()方法实现的。 -
泛型
-
自动装箱与拆箱
自动装箱就是 Java 自动将原始类型值转换成对应的对象,反之,则是拆箱。装箱过程是通过调用包装器的 valueOf 方法实现的,而拆箱过程是通过调用包装器的 xxxValue 方法实现的。
-
方法变长参数
可变参数是在 Java1.5 中引入的一个特性。它允许一个方法把任意数量的值作为参数。
run(String... strs)可变参数在被使用的时候,他首先会创建一个数组,数组的长度就是调用该方法是传递的实参的个数,然后再把参数值全部放到这个数组当中,然后再把这个数组作为参数传递到被调用的方法中。
-
枚举
当我们使用
enmu来定义一个枚举类型的时候,编译器会自动帮我们创建一个final类型的类继承Enum类,所以枚举类型不能被继承。 -
内部类
-
条件编译
—般情况下,程序中的每一行代码都要参加编译。但有时候出于对程序代码优化的考虑,希望只对其中一部分内容进行编译,此时就需要在程序中加上条件,让编译器只对满足条件的代码进行编译,将不满足条件的代码舍弃,这就是条件编译。
Java 语法的条件编译,是通过判断条件为常量的 if 语句实现的。其原理也是 Java 语言的语法糖。根据 if 判断条件的真假,编译器直接把分支为 false 的代码块消除。通过该方式实现的条件编译,必须在方法体内实现,而无法在整个 Java 类的结构或者类的属性上进行条件编译。
-
断言
Java 在执行的时候默认是不启动断言检查的,如果要开启断言检查,则需要用开关
-enableassertions或-ea来开启。其实断言的底层实现就是 if 语言,如果断言结果为 true,则什么都不做,程序继续执行,如果断言结果为 false,则程序抛出 AssertError 来打断程序的执行。 -
数值字面量
在 java 7 中,数值字面量,不管是整数还是浮点数,都允许在数字之间插入任意多个下划线。这些下划线不会对字面量的数值产生影响,目的就是方便阅读。在编译时,编译器会自动去掉下划线。
-
for-each
for-each 的实现原理其实就是使用了普通的 for 循环和迭代器。
-
try-with-resources
-
Lambda 表达式
扩展搜索:
语法盐、语法糖精
参考
参考声明:参考内容来源于网络,本文不保证参考链接的长期有效性,以及参考内容的原创性。
版权声明
本文链接:https://www.chinmoku.cc/java/basic/java-basic/
本博客中的所有内容,包括但不限于文字、图片、音频、视频、图表和其他可视化材料,均受版权法保护。未经本博客所有者书面授权许可,禁止在任何媒体、网站、社交平台或其他渠道上复制、传播、修改、发布、展示或以任何其他方式使用此博客中的任何内容。