Elasticsearch 教程
Elasticsearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 语言开发的,并作为 Apache 许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch 用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在 Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby 和许多其他语言中都是可用的。根据 DB-Engines 的排名显示,Elasticsearch 是最受欢迎的企业搜索引擎,其次是 Apache Solr,也是基于 Lucene。
quote from 百度百科_ElasticSearch
简介
概念简介:
ELK、Elastic Static、ELK Stack?
可以直接看 官网介绍 (耗时2分钟),既形象,又有趣味。
可以总结为: ELK Stack = ElasticSearch + Logstash + Kibana + Beats 。
-
Elastic Stack 的组成
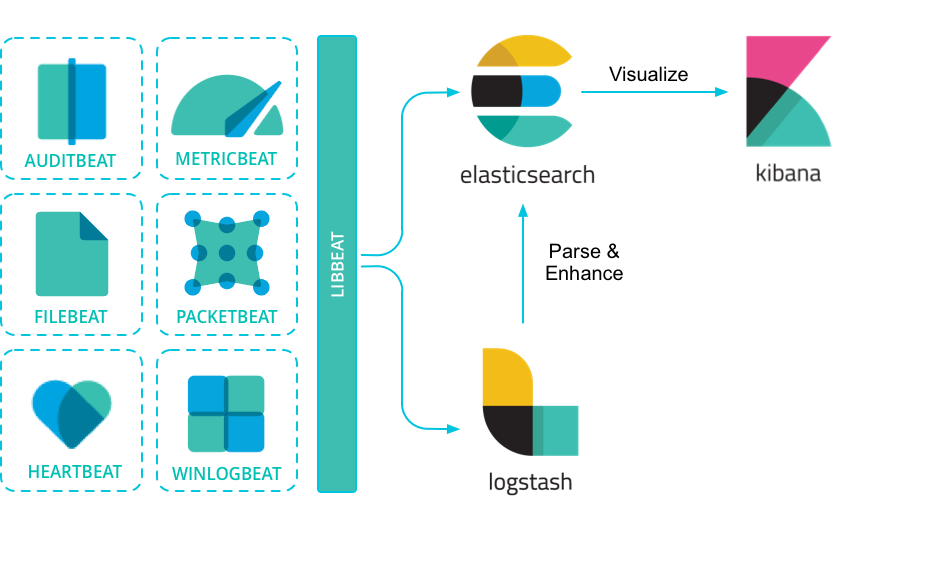
ElasticSearch
Elasticsearch 基于java,是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。

ElasticSearch是Elastic Stack的核心,同时Elasticsearch 是一个分布式、RESTful风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为Elastic Stack的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
Logstash
Logstash 基于java,是一个开源的用于收集,分析和存储日志的工具。
Kibana
Kibana 基于nodejs,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的Web 界面,可以汇总、分析和搜索重要数据日志。
Beats
Beats 是elastic公司开源的一款采集系统监控数据的代理,是在被监控服务器上以客户端形式运行的数据收集器的统称,可以直接把数据发送给 Elasticsearch 或者通过 Logstash 发送给 Elasticsearch ,然后进行后续的数据分析活动。 Beats 由如下组成:
-
Packetbeat:是一个网络数据包分析器,用于监控、收集网络流量信息,Packetbeat 嗅探服务器之间的流量,解析应用层协议,并关联到消息的处理,其支 持 ICMP (v4 and v6)、DNS、HTTP、Mysql、PostgreSQL、Redis、MongoDB、Memcache 等协议;
-
Filebeat:用于监控、收集服务器日志文件,其已取代 logstash forwarder;
-
Metricbeat:可定期获取外部系统的监控指标信息,其可以监控、收集 Apache、HAProxy、MongoDB MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper等服务;
Beats 和 Logstash 其实都可以进行数据的采集,但是目前主流的是使用Beats进行数据采集,然后使用 Logstash 进行数据的分割处理等,早期没有 Beats 的时候,使用的就是 Logstash 进行数据的采集。
安装与运行
本文以 window 安装环境为例,linux环境安装请另行探索。需配置 java 1.8+ 环境。
ElasticSearch 下载安装
-
根据环境选择下载安装包。
-
解压。
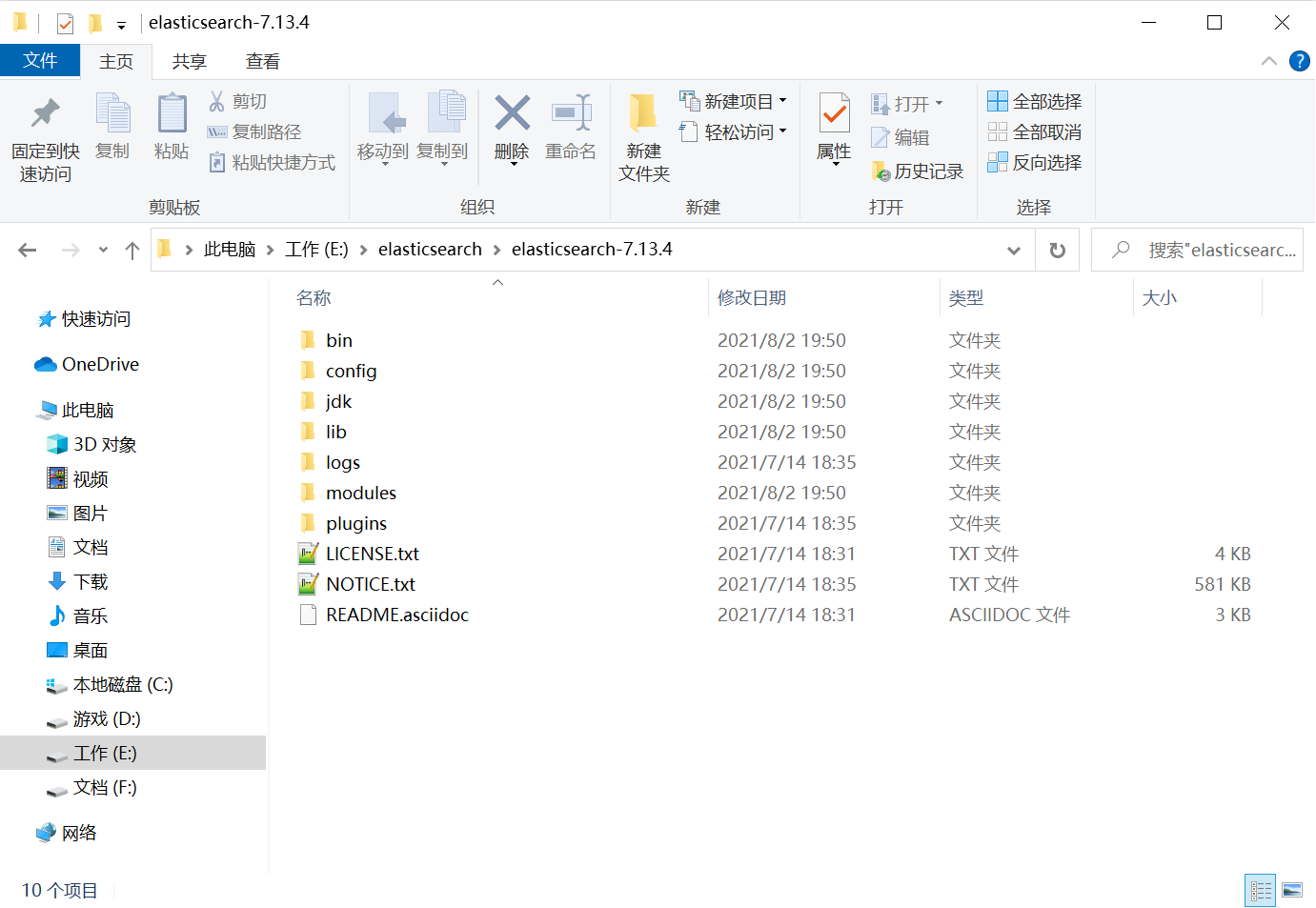
目录结构说明:
-
bin — 用于存放ES启动等脚本文件。
-
config — ES相关配置文件。
-
data — 存放ES当前节点的分片数据,可以直接拷贝到其他节点进行使用。(上图暂未运行,则不存在该文件夹)
-
log — ES运行日志。
-
plugins — 存放常用的插件,如需添加额外的插件,也可以放在这个目录下。
-
-
启动及访问。
双击执行
~\elasticsearch-7.13.4\bin\elasticsearch.bat文件。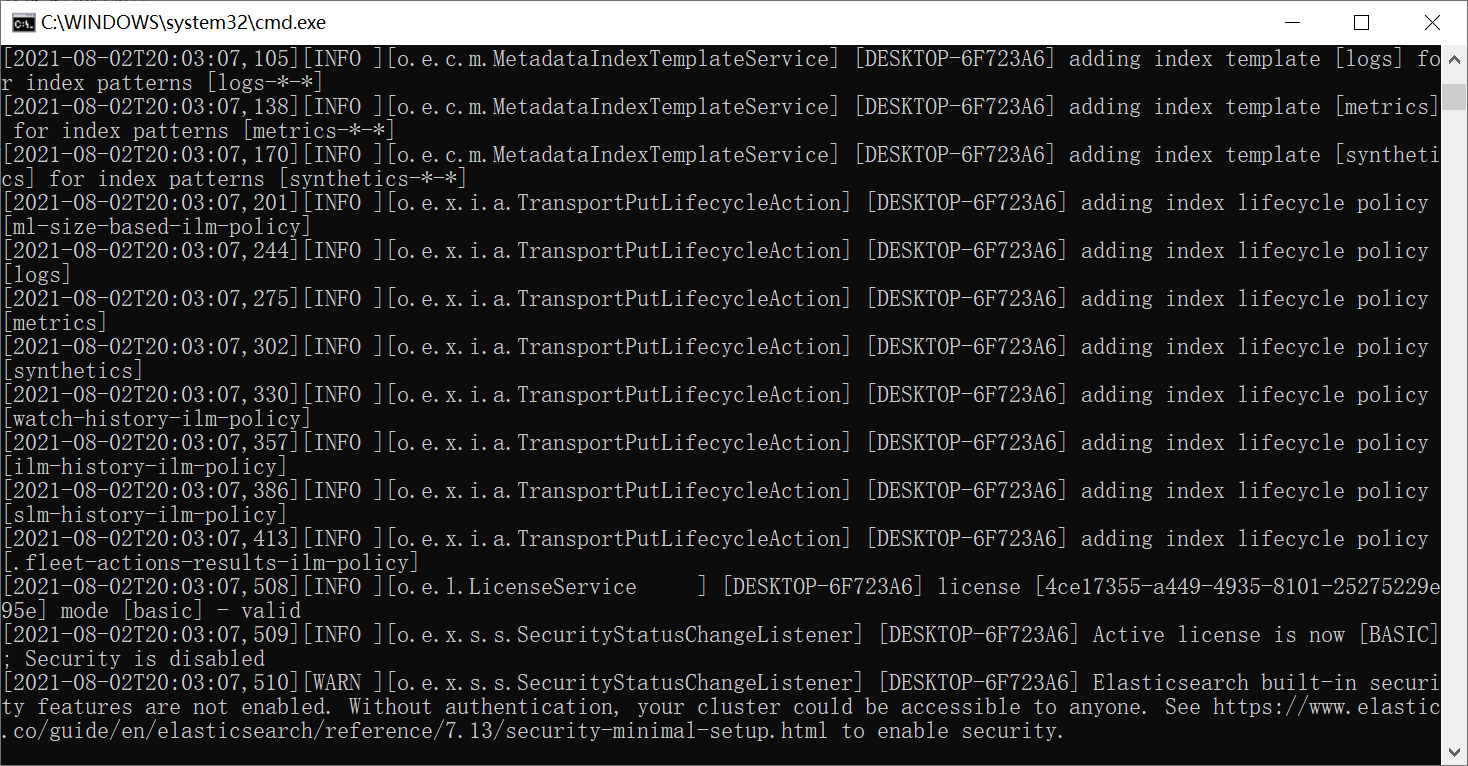
此处启动成功,并提示
Active license is now [BASIC]; Security is disabled,这里是指当前 ES 集群环境未开启 Security ,即没有设置账号密码登录 elasticsearch 服务。(此处可以先忽略)ES 会默认启动两个端口:
-
9200:http协议端口,用于集群之间的通信。
-
9300:tcp通信端口。
浏览器访问 http://127.0.0.1:9200 得到类似如下信息:(同时会在ES解压目录下生成data文件夹)
{ "name" : "DESKTOP-6F723A6", "cluster_name" : "elasticsearch", "cluster_uuid" : "aNleIQnmT_eexKfsuqJ9Og", "version" : { "number" : "7.13.4", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "c5f60e894ca0c61cdbae4f5a686d9f08bcefc942", "build_date" : "2021-07-14T18:33:36.673943207Z", "build_snapshot" : false, "lucene_version" : "8.8.2", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" } -
-
可能出现的问题。
kibana访问时报错:
high disk watermark [90%] exceeded on…
磁盘空间达到90%时,es会将节点上面的索引标为只读,导致不能写入数据。
解决方法:
-
调整磁盘空间比例(使用百分比或gb)
config/elasticsearch.yml
cluster.routing.allocation.disk.watermark.low: 30g cluster.routing.allocation.disk.watermark.high: 20gb -
关闭阀值设置
config/elasticsearch.yml
cluster.routing.allocation.disk.threshold_enabled: false
-
Elasticsearch-head
elasticsearch-head 是一个用于浏览 ElasticSearch 集群并与其进行交互的 Web 项目。
-
下载。
-
启动。
分别执行如下命令:
npm insatall npm run start -
访问。
注:需要先在 Elasticsearch 服务中配置跨域策略,否则会因为跨域而连接不上。打开
~\elasticsearch-7.13.4\config\elasticsearch.yml并添加如下配置后重启即可:http.cors.enabled: true http.cors.allow-origin: "*"在浏览器中访问:http://127.0.0.1:9100 并连接,连接成功后视图如下:
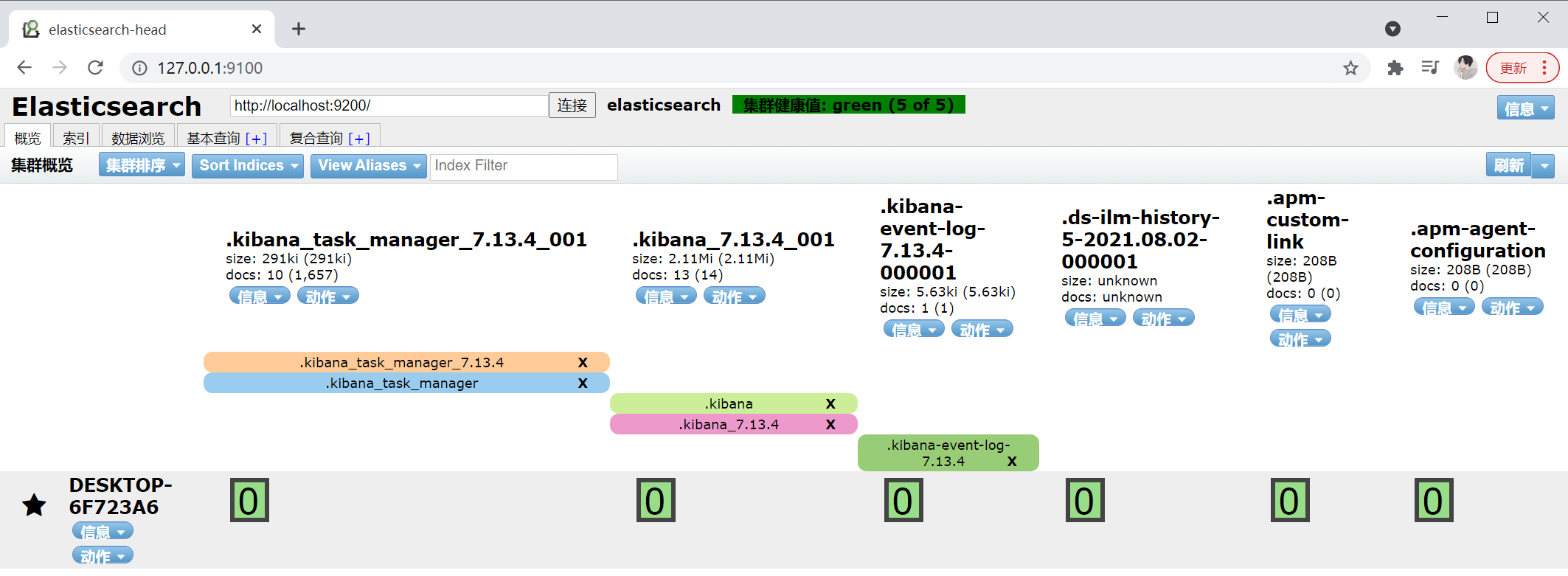
注:以上截图显示了部分数据,是
kibana连接时自动生成的,如还未连接则查询为空。 -
健康值说明。
-
绿色:最健康的状态,代表所有的分片包括备份都可用。
-
黄色:基本的分片可用,但是备份不可用(也可能是没有备份)。
-
红色:部分的分片可用,表明分片有一部分损坏。此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好。
-
灰色:未连接到服务。
-
Kibana 下载安装
Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
注意:尽量保持 kibana 版本与 elasticsearch 版本一直。
-
根据环境选择下载安装包。
-
配置。
打开并编辑
~\kibana-7.13.4\config\kibana.yml文件:server.host: "127.0.0.1" elasticsearch.hosts: ["http://127.0.0.1:9200"]
-
启动及访问。
双击执行
~\kibana-7.13.4\bin\kibana.bat文件(需要先启动elasticsearch)。出现
http server running at http://127.0.0.1:5601即表示启动成功。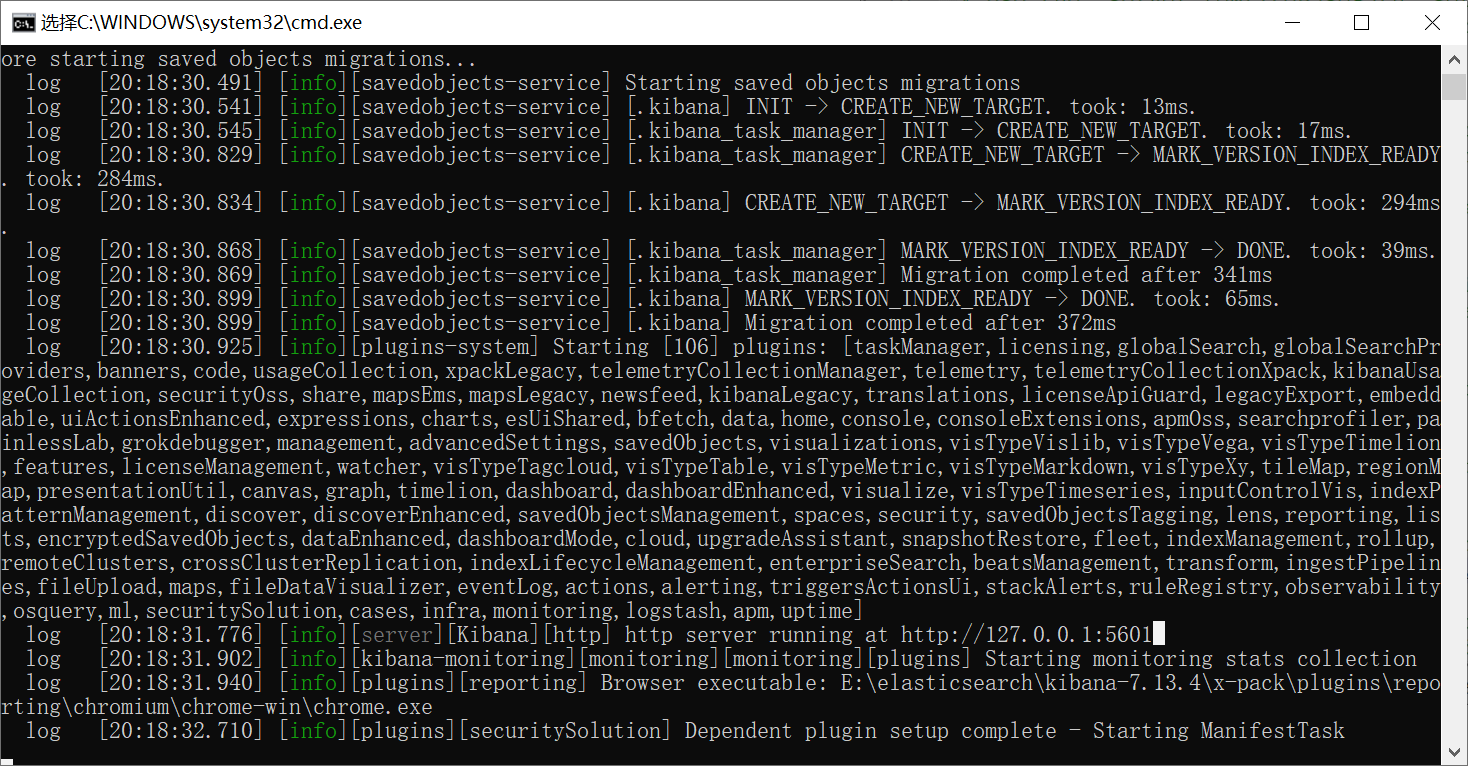
在浏览器中访问:http://127.0.0.1:5601 视图如下:
-
可能出现的问题。
启动警告:
Session cookies will be transmitted over insecure connections. This is not recommended.
Generating a random key for xpack.security.encryptionKey. To prevent sessions from being invalidated on restart, please set xpack.security.encryptionKey in kibana.yml
可尝试在文件中添加如下配置信息:
xpack.encryptedSavedObjects.encryptionKey: encryptedSavedObjects12345678909876543210 xpack.security.encryptionKey: encryptionKeysecurity12345678909876543210 xpack.reporting.encryptionKey: encryptionKeyreporting12345678909876543210
注:ES图形化插件除了 kibana 外,还有 ElasticSearch Head 、 elasticsearch-sql 等,但视图风格有点老。elasticsearch、logstash、kibana 合称 ELK 。
Logstash 下载安装
注意:尽量保持 logstash 版本与 elasticsearch 版本一直。
-
根据环境选择下载安装包。
-
配置启动。
在
logstash-7.13.4\bin目录下执行如下命令:logstash -e “input { stdin {} } output { stdout {} }”
当出现
Piplines running...时,输入任意字符串进行测试,如下图: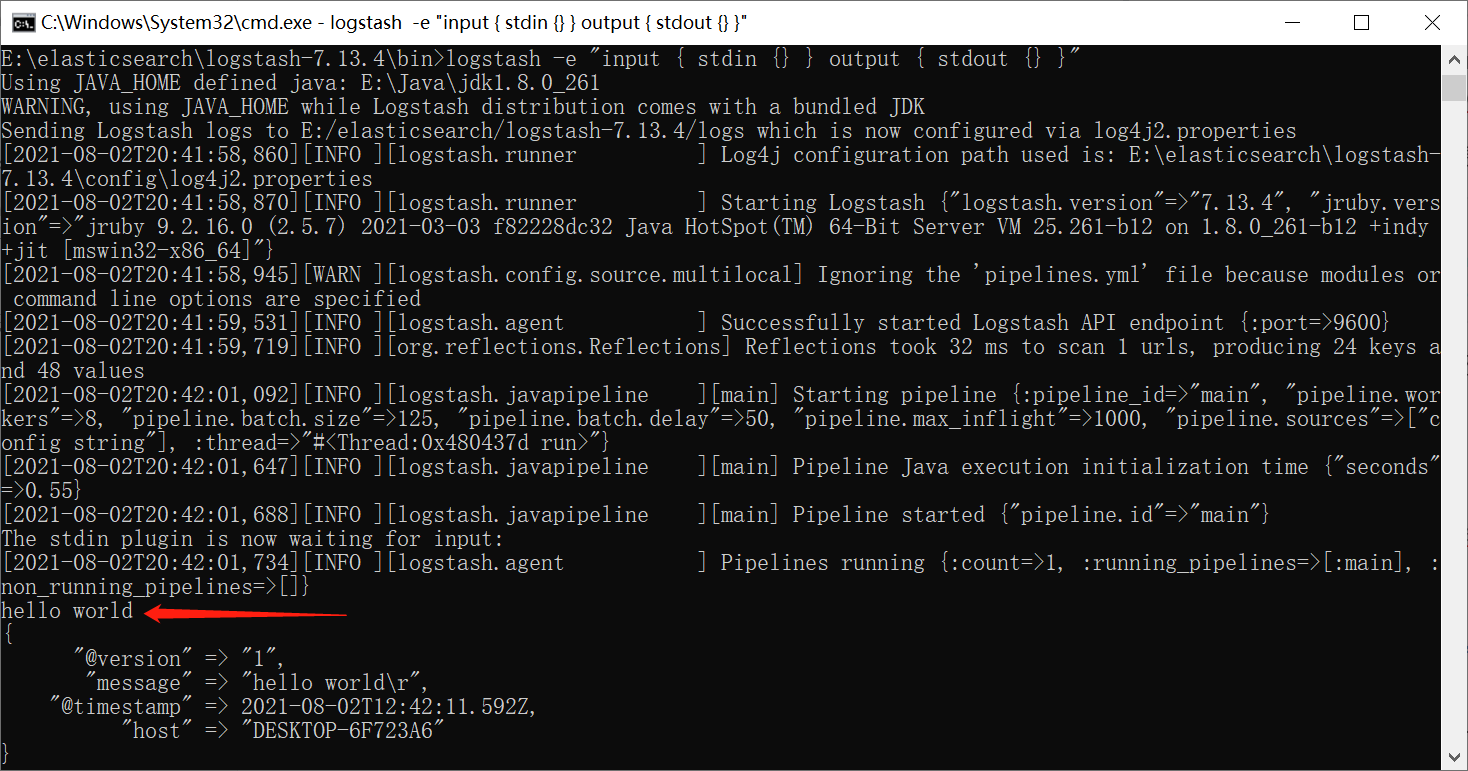
ES 相关概念
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
Elasticsearch 与传统关系型数据库关系映射如下:
| Relational DB | Elasticsearch | 描述 |
|---|---|---|
| Databases | Indices | |
| Tables | Types | |
| Rows | Documents | |
| Columns | Fields |
核心概念
-
_index(索引)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。(可类比mysql中的数据库进行理解)
-
_type(类型)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。(可类比mysql中的表进行理解)
-
field(字段)
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识 。
-
mapping(映射)
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。(相当于mysql中的创建表的过程,设置主键外键等等)
-
document(文档)
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。( 插入索引库以文档为单位,类比与数据库中的一行数据)
-
cluster(集群)
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由 一个唯一的名字标识,这个名字默认就是 elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
-
node(节点)
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一 个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的 时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对 应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫 做 elasticsearch 的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做 elasticsearch 的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点, 这时启动一个节点,会默认创建并加入一个叫做 elasticsearch 的集群。
-
shards & replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:
-
允许你水平分割/扩展你的内容容量。
-
允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
-
RESTful API
在 Lucene 中,创建索引是需要定义字段名称以及字段类型的,在 Elasticsearch 中提供了非结构化的索引,就是不需要创建索引结构,即可写入数据到索引中,实际上在 Elasticsearch 底层会进行结构化操作,此操作对用户是透明的。
推荐使用 Postman 作为接口调用工具。在调用下面的接口前,请先自行添加一些测试数据。
-
创建索引
// PUT http://127.0.0.1:9200/test_index(命名随意) { "settings": { "index": { "number_of_shards": "2", // 分片数 "number_of_replicas": "0" // 副本数 } } } -
删除索引
// DELETE http://127.0.0.1:9200/test_index { "acknowledged": true }注:删除操作不会立即被删除,而是被标记为删除。
-
插入数据
// POST http://127.0.0.1:9200/test_index/user/1001 { "id": 1001, "name": "张三", "age": 22, "sex": "男" }响应信息如下:
// response info: { "_index": "test_index", "_type": "user", "_id": "1001", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }在
elasticsearch-head可查看到如下信息: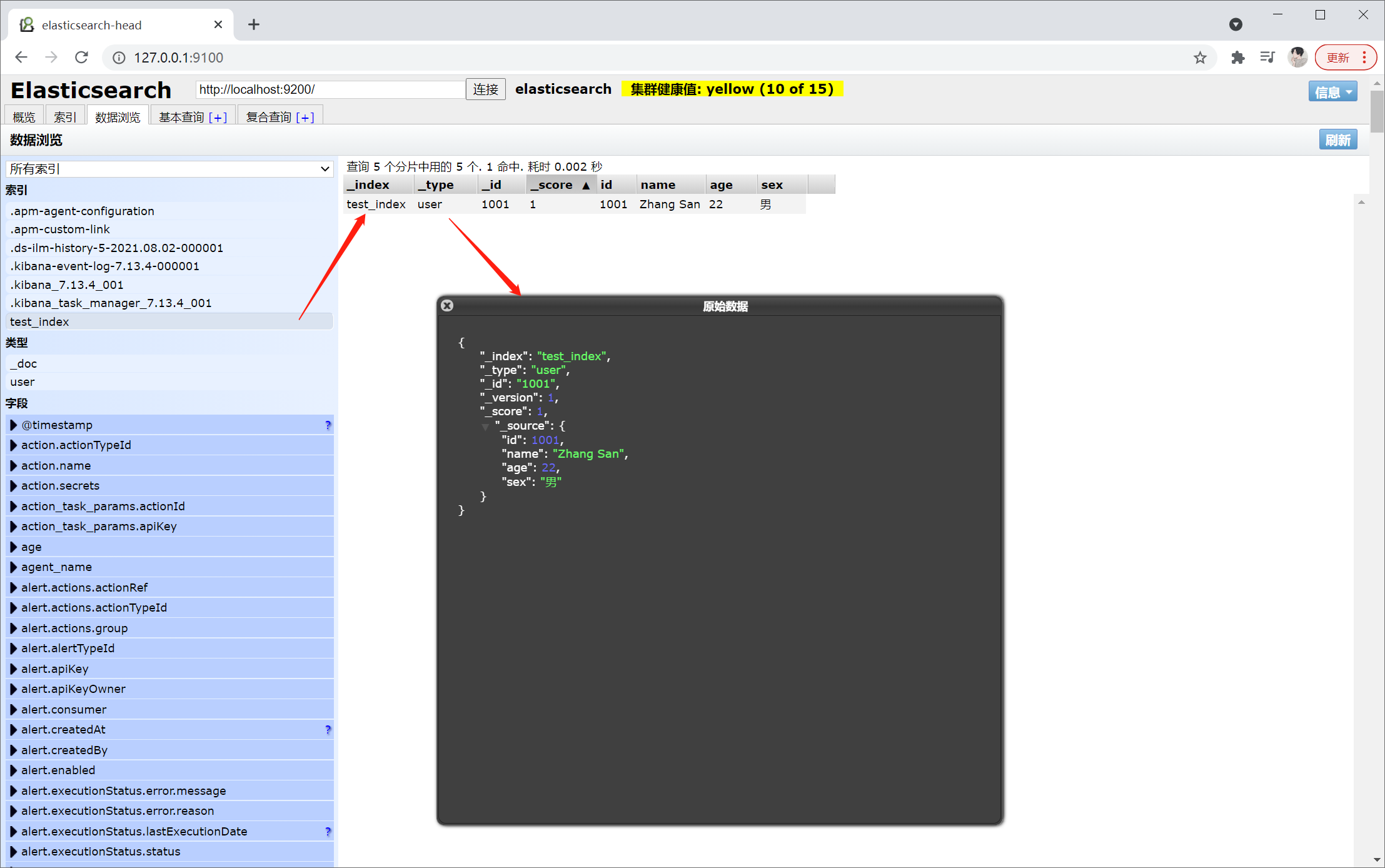
在插入数据时,如果不再 URI 中指定 ID ,ES 会自动生成一个唯一的 ID 标识。
-
更新数据
在 Elasticsearch 中,文档数据是不能修改的,但是可以通过覆盖的方式进行更新。
// PUT http://127.0.0.1:9200/test_index/user/1001 { "id": 1001, "name": "张珊", "age": 20, "sex": "女" }通过这种方式更新数据,默认是全量更新,即移除旧有数据,所有数据都以新的请求数据为准,未传入字段则为空。
局部更新方式如下:
// POST http://127.0.0.1:9200/test_index/user/1001/_update { "doc": { "name": "张珊" } }注:局部参数需要用
doc进行包装。 -
搜索数据
-
查询单条数据:
GET http://127.0.0.1:9200/test_index/user/1001
{ "_index": "test_index", "_type": "user", "_id": "1001", "_version": 2, "_seq_no": 1, "_primary_term": 1, "found": true, "_source": { "id": 1001, "name": "张珊", "age": 20, "sex": "女" } } -
查询全部数据:(默认返回10条)
-
关键字搜索数据
-
-
DSL 搜索
// POST http://127.0.0.1:9200/test_index/user/_search { "query": { "match": { "age": 20 } } }过滤查询:(过滤小于20岁的女性)
// POST http://127.0.0.1:9200/test_index/user/_search { "query": { "bool": { "filter": { "range": { "age": { "lt": 20 } } }, "must": { "match": { "sex": "女" } } } } }全文搜索:
// POST http://127.0.0.1:9200/test_index/user/_search { "query": { "match": { "name": "张三 张珊" } } } -
高亮显示
// POST http://127.0.0.1:9200/test_index/user/_search { "query": { "match": { "name": "张三 张珊" } }, "highlight": { "fields": { "name": {} } } } -
聚合
// POST http://127.0.0.1:9200/test_index/user/_search { "aggs": { "all_interests": { "terms": { "field": "age" } } } } -
判断数据是否存在
HEAD http://127.0.0.1:9200/test_index/user/1001
存在则返回200,不存在则返回404。
-
批量查询
// POST http://127.0.0.1:9200/test_index/user/_mget { "ids": ["1001", "abcd"] }如对应 ID 不存在,查询结果不会受 404 影响。
-
分词查询
// POST http://127.0.0.1:9200/test_index/user/_analyze { "analyzer": "ik_max_word", "text": "IK中文分词器" }分词器后续有单独讲解。
通过上述 RESTful API 示例,我们已经基本熟悉了如何通过接口对 ES 数据进行操作。更多的操作没有强行记住的必要,也并不是本文的重点,这里也就不赘述了,需要用到时,再搜索相关方法即可。本文省略部分主要包括如下内容:
-
批量查询
-
_bulk操作
-
分页
-
映射:类型自动匹配
-
结构化查询:
-
term / terms
-
range
-
exists
-
match:标准查询
-
bool: must / must_not / should
-
-
过滤查询
查询和过滤的对比。
做精确匹配搜索时,最好用过滤语句,因为过滤语句可以缓存数据。
中文分词器
elasticsearch 默认使用标准分词器,对于中文的支持并不友好,可以选择安装 IK 或 smartcn 等中文分词器(这里以IK为例)。
下载安装
-
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
需注意选择与 elasticsearch 相匹配的分词器版本。
-
解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为analysis-ik (其他名字也可以,目的是不要重名)
-
重新启动ElasticSearch,即可加载IK分词器。
如若启动报错,可通过
~\elasticsearch-7.6.2\logs\elasticsearch.log文件进行排查。
分词测试
启动 elasticsearch.bat ,使用 Postman 进行如下测试:
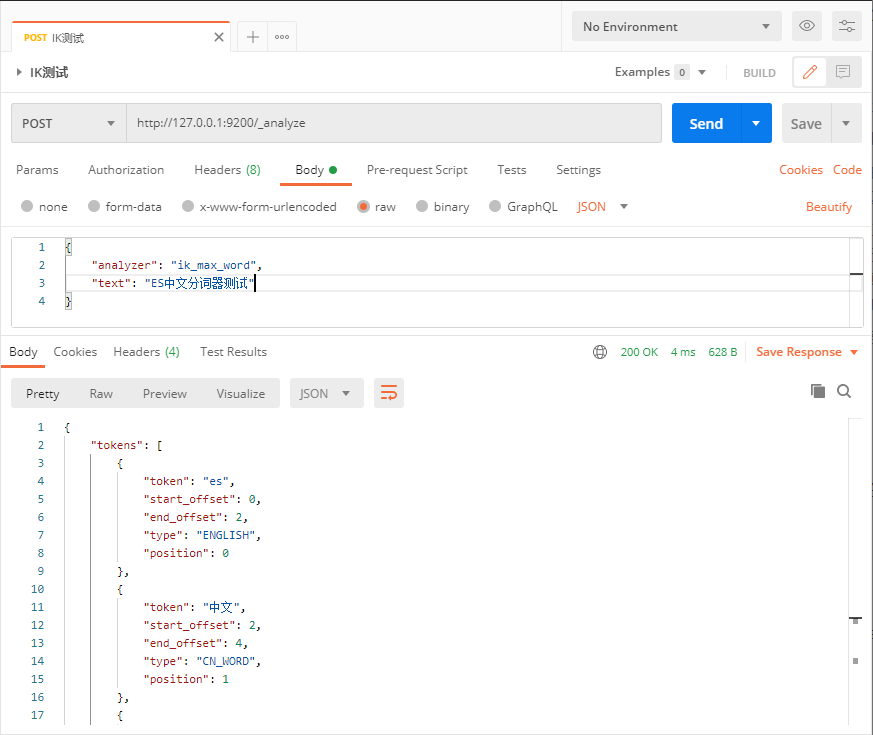
测试结果:
{
"tokens": [
{"token":"es","start_offset":0,"end_offset":2,"type":"ENGLISH","position":0},
{"token":"中文","start_offset":2,"end_offset":4,"type":"CN_WORD","position":1},
{"token":"分词器","start_offset":4,"end_offset":7,"type":"CN_WORD","position":2},
{"token":"分词","start_offset":4,"end_offset":6,"type":"CN_WORD","position":3},
{"token":"器","start_offset":6,"end_offset":7,"type":"CN_CHAR","position":4},
{"token":"测试","start_offset":7,"end_offset":9,"type":"CN_WORD","position":5}
]
}全文搜索
全文搜索包括两个最重要的方面:
-
相关性(Relevance)
它是评价查询与其结果间的相关程度,并根据这种相关程度对结果进行排名的一种能力,这种计算方式可以是 TF/IDF 方法、地理位置临近、模糊相似,或其他某些算法。
-
分词(Analysis)
它是将文本块转换为有区别的、规范化的 token 的一个过程,目的是为了创建倒排索引以及查询倒排索引。
使用 IK 分词器创建索引示例:
{
"settings": {
"number_of_shards": "6",
"number_of_replicas": "1",
// 全索引指定分词器
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"novel": {
"properties": {
"id":{
"type": "long",
"store": true
},
"title": {
"type": "text",
"store": true,
"analyzer":"ik_smart"// 指定字段分词器
},
"content": {
"type": "text",
"store": true
},
"description": {
"type": "text",
"store": true
}
}
}
}
}-
ik_max_word :会将文本做最细粒度的拆分,会穷尽各种可能的组合。
-
ik_smart :会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
单词查询
// POST http://127.0.0.1:9200/novel/archive/_search
{
"query": {
"match": {
"title": "中国"
}
},
"highlight": {
"fields": {
"title": {}
}
}
}多词查询
// POST http://127.0.0.1:9200/novel/archive/_search
{
"query": {
"match": {
"title": {
"query": "中国 疫情",
// 匹配度需要根据实际使用进行调整
// "minimun_should_match": "80%", // 匹配度,比例越大,匹配越严格
"opeartor": "and" // 默认为 or
}
}
},
"highlight": {
"fields": {
"title": {}
}
}
}组合查询
有点绕,根据使用场景再进行详细的研究即可,此处略去。
但此处有个 权重 的概念,需要稍加留意。
Elasticsearch 集群
集群节点
Elasticsearch 的集群是由多个节点组成的,通过 cluster.name 设置集群名称,并且勇于区分其他的集群,每个节点通过 node.name 指定节点的名称。
在 Elasticsearch 中,节点的类型主要有4种:
-
master 节点
-
配置文件中
node.master属性为 true (默认为true),就有资格被选为 master 节点。 -
master 节点用于控制整个集群的操作。比如创建或删除索引,管理其他非 master 节点等。
-
-
data 节点
-
配置文件中
node.data属性为 true (默认为true),就有资格被设置成 data 节点。 -
data 节点主要用于执行数据相关的操作。比如文档的 CRUD 。
-
-
客户端节点
-
配置文件中
node.master属性和node.data属性均为 false 。 -
该节点不能作为 master 节点,也不能作为 data 节点。
-
可以作为客户端节点,用于响应用户的请求,把请求转发到其他节点。
-
-
部落节点
- 当一个节点配置
tribe.*的时候,它是一个特殊的客户端,它可以连接多个集群,在所有连接的集群上执行搜索和其他操作。
- 当一个节点配置
集群搭建
Java 客户端
在 Elasticsearch 中,为 java 提供了两种客户端,一种时 REST 风格的客户端,另一种是 Java API 的客户端。
准备工作:
-
创建测试项目
-
添加pom依赖
REST 客户端
Elasticsearch 又提供了两种 REST 客户端,一种时低级客户端,一种时高级客户端。
-
Java Low Level REST Client
官方提供的低级客户端。该客户端通过 http 来连接 Elasticsearch 集群。用户在使用该客户端时需要将请求数据手动拼接陈 Elasticsearch 所需 JSON 格式进行发送,收到响应时同样也需要将返回的 JSON 数据手动封装成对象。虽然麻烦,不过该客户端兼容所有的 Elasticsearch 版本。
-
Java High Level REST Client
官方提供的高级客户端。该客户端基于低级客户端实现,它提供了很多辩解的 API 来解决低级客户端需要手动转换数据格式的问题。
低级客户端
高级客户端
参考
版权声明
本文链接:https://www.chinmoku.cc/java/advanced/elasticsearch-tutorial/
本博客中的所有内容,包括但不限于文字、图片、音频、视频、图表和其他可视化材料,均受版权法保护。未经本博客所有者书面授权许可,禁止在任何媒体、网站、社交平台或其他渠道上复制、传播、修改、发布、展示或以任何其他方式使用此博客中的任何内容。